натрапив, прочитав, злякався… треба спробувати, поки є вільна машина: інтенсивний екстремальний курс адміністрування linux (чи радше задачник) на reddit’івському r/linuxadmin.
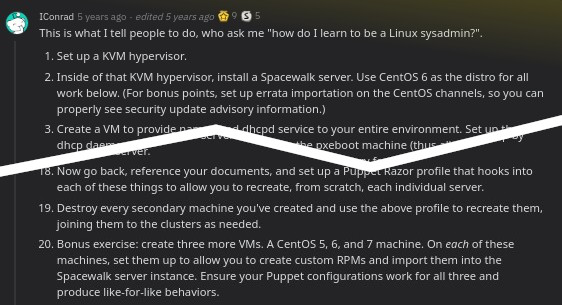
поновлення (2020-08-14). дійшли руки, мабуть, взятися за цей проєкт самонавчання. очі бояться, руки роблять? побачимо. замість додавати новий допис, вирішив продовжити цей. ну все, понеслась…
зміст
- 0. підготовка
- 1. гіпервізор з kvm
- 2. сервер spacewalk
- 3. сервер dhcp/dns
- додатки
/i\ щодо нотації команд та інших позначок:
#>— команда від root’а (або з sudo);$>— команда від кристувача;##або#— коментар;- /i\ ― заувага;
- /!\ ― проблема.
0. підготовка
0.1. тестовий стенд
як планував, за навчальний стенд беру купований на kijiji за 20$ asus cm6340 — побачимо, чи вистачить його:
- процесор: intel core i5-3470;
- пам’ять: 16 гб (4×4 гб)
- диски:
- ssd 120 гб (kingston sv300s3)
- hdd 500 гб (western digital wd5000aakx)
- hdd 500 гб (western digital wd5000aakx)
- мережа:
- ethernet: realtek rtl8111/8168/8411 (інтегрований)
- wifi: ralink rt3090 (802.11n)
- ethernet: intel expi9301ctblk (доставив, аби не лежало без діла)
під питанням, чи цього вистачить.

0.2. встановлення debian
все зрозуміло і знайомо, за винятком… розподілу дисків специфічно під задачу (гіпервізор на kvm’і) — як краще? готових рецептів не знайшов, лише підказки. ось перша спроба, подякую за критику:
- ssd 120 гб (sda):
- 512 мб — efi (fat32, прапорці boot та esp, sda0);
- 32 гб — swap (sda1);
- 87 гб — корінь (/, ext4, sda2);
- hdd 500 гб (sdb):
- 500 гб — фізичний том lvm (sdb1);
- hdd 500 гб (sdc):
- 500 гб — фізичний том lvm (sdc1).
два диски по 500 гб об’єднав lvm’ом у групу (roku_vg0) і віддав під один терабайний логічний розділ (ext4, roku_lv0), куди монтується /var (віртуальні машини kvm наче будуть у /var/lib/libvirt).
на користувацьких машинках звик виділяти окремий розділ для /home, але тут не бачу сенсу цього робити. щодо свопа — думав, чи потрібно стільки на сервері… але нехай буде: все-одно ssd завеликий для простої хост-машини під kvm.
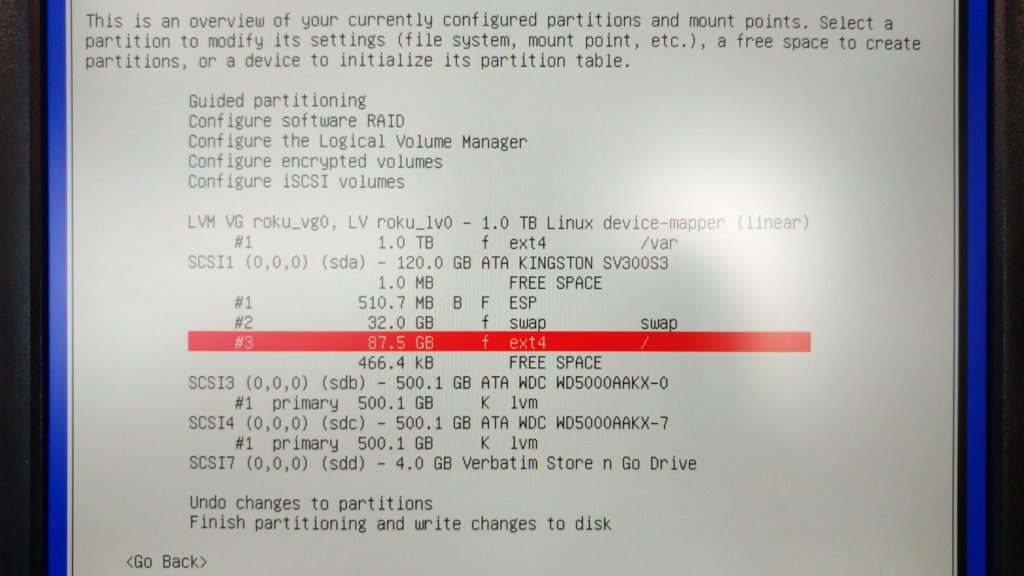
для чистоти експерименту не встановлюю стільницю (потрібно прибрати галочку біля debian desktop environment не етапі software selection, інакше затягнеться gnome за замовчуванням), лише сервер ssh.
0.3. налаштування «дрібничок»
після перезавантаження тестовий сервер майже готовий… але ще рано відключати монітор: потрібен доступ по ssh, але за якою адресою? за замовчуванням debian питає dhcp, і вдома для простоти я уникаю статичних адрес, тож найперший крок — занотувати адреси mac обох мережевих адаптерів (cm6340 має eth та wifi) і зафіксувати x.x.x.6/24 для сервера (roku — шість японською).
з інших необхідних налаштувань:
традиційне поновлення пропускаю (бо встановлював з образу netinst, він тягне все нове):
#> apt-get update && apt-get upgrade
sudo — встановити й додати себе до відповідної групи (знадобиться вийти/зайти):
#> apt-get install sudo && adduser tivasyk sudo
path — «з коробки» debian 10 має «криве» налаштування path, і команди з /usr/sbin не знаходяться (зокрема, fdisk); лікується додаванням рядка до ~/.bashrc:
PATH=$PATH:/usr/sbin
ssh — «з коробки» дозволяє підключення root’а, бажано одразу «поремонтувати» (PermitRootLogin no в конфігу /etc/ssh/sshd_config) і перезавантажити сервіс:
#> systemctl restart sshd
lf — (опційно) простий і вже звичний для мене файловий мереджер для консолі (увага! розпаковування першого ліпшого бінарника просто до /usr/bin — прямий шлях до нехороших наслідків):
$> wget -qO- https://github.com/gokcehan/lf/releases/latest/download/lf-linux-amd64.tar.gz | sudo tar -C /usr/bin -zxvf -
tcpdump ― (опційно?) гадаю, що знадобиться на якомусь етапі, щоби траблшутити мережу з віртуальними машинами… враховуючи, що в мене до цього часу був лише куций досвід з iptables:
#> apt-get install tcpdump
drill — (опційно?) ще один інструмент, який може знадобитися (аналог nslookup, віндузятники):
#> apt-get isntall ldnsutils
здається, це все про підготовку: є доступ по ssh, можна відключити монітор і братися до першого завдання.
1. гіпервізор з kvm
задача: «1. Set up a KVM hypervisor» (reddit).
1.1. встановлення гіпервізора
перевірку підтримки віртуалізації можу пропустити, але для повноти картини:
#> if [[ $(grep "vmx\|svm" -c /proc/cpuinfo) -gt 0 ]]; then echo "OK"; fi
OK
гуглив якусь зрозумілу (не примітивну) підказку зі встановлення kvm в debian’і — знаходяться переважно злизані індійськими одмінами одне в одного «сутри», де бракує пояснень і важливих деталей, і починаються з пропозиції зробити apt-get install kvm, що є повна маячня в сучасному debian’і… більше довіри маю до вікі debian.
встановлення лише потрібного, без «рекомендацій» (які намагаються затягнути купу непотребу для стільничого середовища, зайві 230 мб):
#> apt-get install --no-install-recommends qemu-kvm libvirt-clients libvirt-daemon-system virtinst
/i\ згодом виявиться (див. 1.2.7.спроба встановлення віртуальної машини), що потрібен ще qemu-utils.
перевірка, чи працює демон libvirt (повинен бути active (running)):
#> systemctl status libvirtd
дати доступ собі (не root) до консолі гіпервізора (virsh):
$> sudo adduser $USER libvirt
перевірка доступу:
$> virsh --connect qemu:///system list --all
команда працює; очікувано, перелік порожній: віртуальних машин ще немає. здається, це був найпростіший крок з усього задачника.
/i\ ще розбираюся з усім цим, але… якщо забути про --connect qemu:///system, вірш працює з контекстом (сесією) поточного користувача.
1.2. налаштування віртуальної мережі
на цьому етапі я сильно задумався, вивчаючи варіанти налаштування віртуальної мережі для тестовго стенду… найдетальнішою підказкою з переліку видається «libvirt networking handbook»; з перелічених там п’яти варіантів, вагаюся між натованою і маршрутизованою мережами: найбільшого бубна вимагає (і обіцяє найдовшу бороду) натована мережа — отже, це найцікавіше.
/i\ довідник arch linux тішить детальною статтею про налаштування мережевих мостів на linux: brctl не потрібен (тому й не йде з debian тепер) — достатньо нового «швейцарського ножика» ip:
## brctl addbr br0 (застаріло, але працює, якщо встановити bridge-utils)
#> ip link add name br0 type bridge && ip link set br0 up
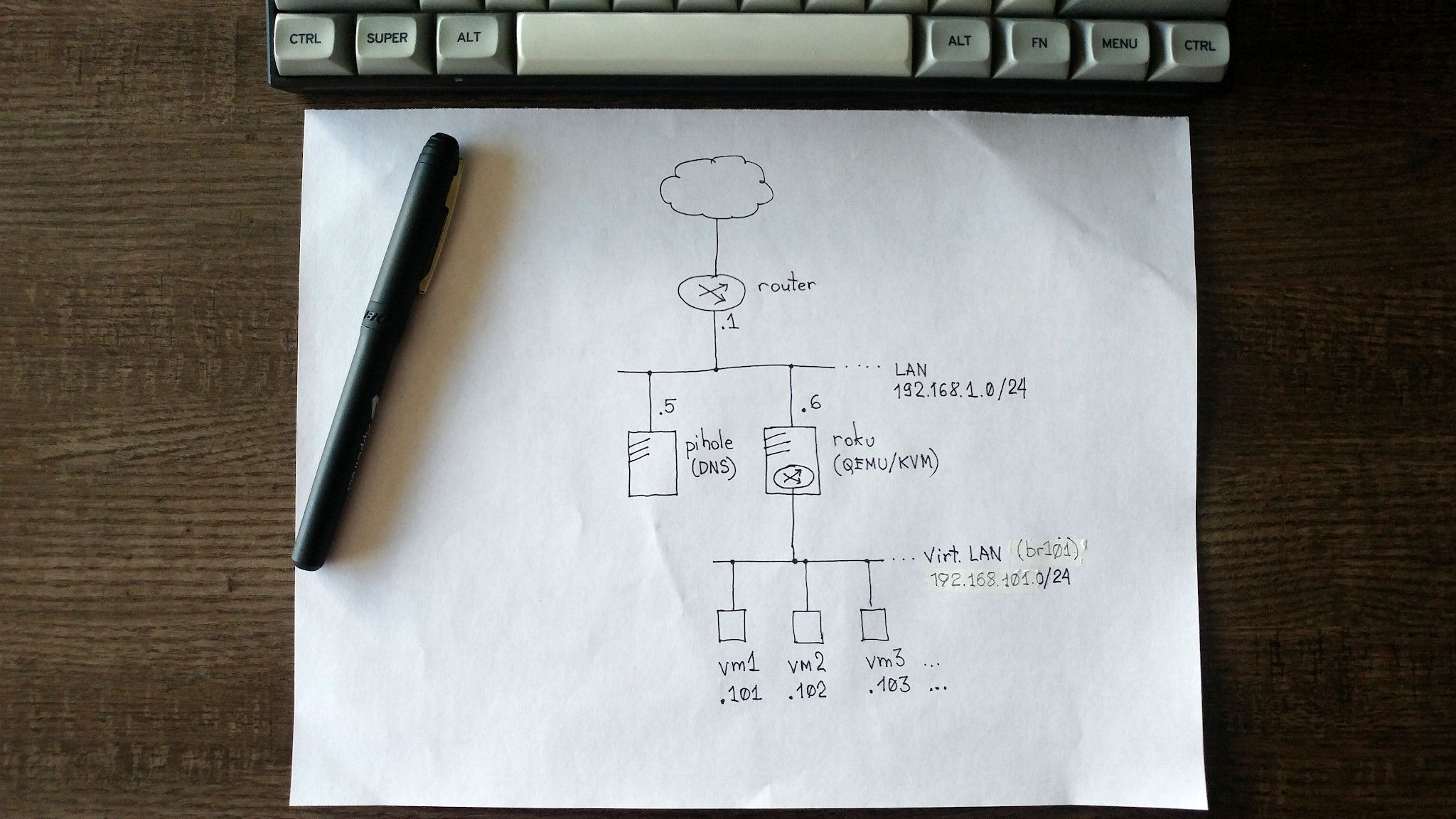
вихідні дані:
- домашня мережа — 192.168.1.0/24 (але може бути будь-яка, для цього й обрав nat-ований варіант, щоби не торкатися конфігурації зовнішньої відносно тестлабу мережі);
- сервер віртуалізації ― 192.168.1.6/24 (roku.lan, інтерфейс
enp3s0); - шлюз (default route) — 192.168.1.1 (router.lan);
- сервер dns (upstream) — 192.168.1.5 (pihole.lan);
- сервер віртуалізації ― 192.168.1.6/24 (roku.lan, інтерфейс
- віртуальна мережа — 192.168.101.0/24;
- сервер віртуалізації / віртуальний маршрутизатор — 192.168.101.1/24 (інтефейс/міст
virbr101); - віртуальні машини — 192.168.101.101..254.
- сервер віртуалізації / віртуальний маршрутизатор — 192.168.101.1/24 (інтефейс/міст
накидав чернетку мережної схеми, час спробувати.
1.2.1. відключити мережу default?
за підказкою, найперше — відключити мережу default, яку libvirt (менеджер віртуалок на qemu/kvm) створює за замовчуванням. але видалити її не можна:
перевірка:
$> virsh --connect qemu:///system net-list --all
Name State Autostart Persistent
----------------------------------------------
default inactive no yes
спроба видалення:
$> virsh --connect qemu:///system net-destroy default
error: Failed to destroy network default
error: Requested operation is not valid: network 'default' is not active
за потреби можна скасувати автостарт (але з коробки він відключений):
$> virsh --connect qemu:///system net-autostart --disable default
1.2.2. віртуальний міст з фіксованою mac-адресою
щоби обійти проблему з «випадковою» mac-адресою віртуального моста після перезавантаження (тиць), можна щоразу першим підключати «підставний» (dummy) інтерфейс з фіксованим mac-ом.
генеруємо випадковий mac (один раз); перші три байти 52:54:00 зафіксовано (стандартно для kvm), наступні три з /dev/urandom:
#> hexdump -vn3 -e '/3 "52:54:00"' -e '/1 ":%02x"' -e '"\n"' /dev/urandom
52:54:00:89:24:f2
створюємо «підставний» інтерфейс virbr101-dummy (можна не «піднімати»):
#> ip link add virbr101-dummy address 52:54:00:89:24:f2 type dummy
створюємо віртуальний міст virbr101, першим підключаємо до нього цей «підставний» інтерфейс і піднімаємо:
#> ip link add name virbr101 type bridge
#> ip link set virbr101-dummy master virbr101
#> ip link set virbr101 up
перевірка (див. mac-адресу моста virbr101):
$> ip link list type bridge
7: virbr101: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:89:24:f2 brd ff:ff:ff:ff:ff:ff
наступна проблема в тому, що всі ці налаштування діють лише до перезавантаження сервера; щоби зробити їх персистентними, потрібно додати ці налаштування до /etc/network/interfaces, або (краще) створити файл /etc/network/interfaces.d/virbr101 і додати все це туди:
# підставний інтерфейс для фіксування mac-адреси мосту virbr101
auto virbr101-dummy
iface virbr101-dummy inet manual
pre-up /sbin/ip link add virbr101-dummy type dummy
up /sbin/ip link set virbr101-dummy address 52:54:00:89:24:f2
# міст virbr101 для віртуальних машин kvm
auto virbr101
iface virbr101 inet static
pre-up /sbin/ip link set virbr101-dummy up
pre-up /sbin/ip link add virbr101 type bridge
up /sbin/ip link set virbr101-dummy master virbr101
address 192.168.101.1
netmask 255.255.255.0
/i\ підказка використовує brctl для маніпуляцій з мостом — довелося переписати під ip.
після перезапуску сервера міст virbr101 повинен бути up і з фіксованою mac-адресою (type bridge опційно):
$> ip link list type bridge
5: virbr101: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:89:24:f2 brd ff:ff:ff:ff:ff:ff
1.2.3. маршрутизація ipv4
перевірка на сервері віртуалізації, чи ввімкнно маршрутизацію (мене цікавить лише ipv4):
$> cat /proc/sys/net/ipv4/ip_forward
0
альтернативно можна так:
$> sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0
нулик в обох випадках означає, що маршрутизацію вимкнено. вмикаємо «на льоту» (не сплутати sysctl з systemctl):
#> sysctl -w net.ipv4.ip_forward=1
/i\ в підказці радять одразу ввімкнути параметр, що відповідає за маршрутизацію на всіх мережевих інтерфейсах — але схоже, що debian це робить сам, коли перемикати ip_forward, тож нема потреби робити руками (хіба що в інших дистрибутивах це налаштовано інакше з міркувань безпеки?):
#> sysctl -w net.ipv4.conf.all.forwarding=1
знадобиться зробити цю зміну персистентною (інакше — до перезавантаження), розкоментувавши відповідний рядо в /etc/sysctl.conf:
# Uncomment the next line to enable packet forwarding for IPv4
net.ipv4.ip_forward=1
гаразд, на цьому етапі машина roku має три активних мережевих інтерфейси:
* локальна петля lo (127.0.0.1/24);
* фізичний enp3s0 (192.168.1.6/24);
* віртуальний міст virbr101 (192.168.101.1/24).
1.2.4. трансляція адрес (nat-ування) за допомогою iptables
чи не найцікавіший короткий, але досить детальний посібник з iptables знайшовся на booleanworld.com.
debian має netfilter/iptables «з коробки», але конфігурація порожня (за винятком стандартної політи ки accept) — все відкрито, без nat-ування ані маршрутизації:
#> iptables -t filter -L -v
#> iptables -t nat -L -v
#> iptables -t mangle -L -v
#> iptables -t raw -L -v
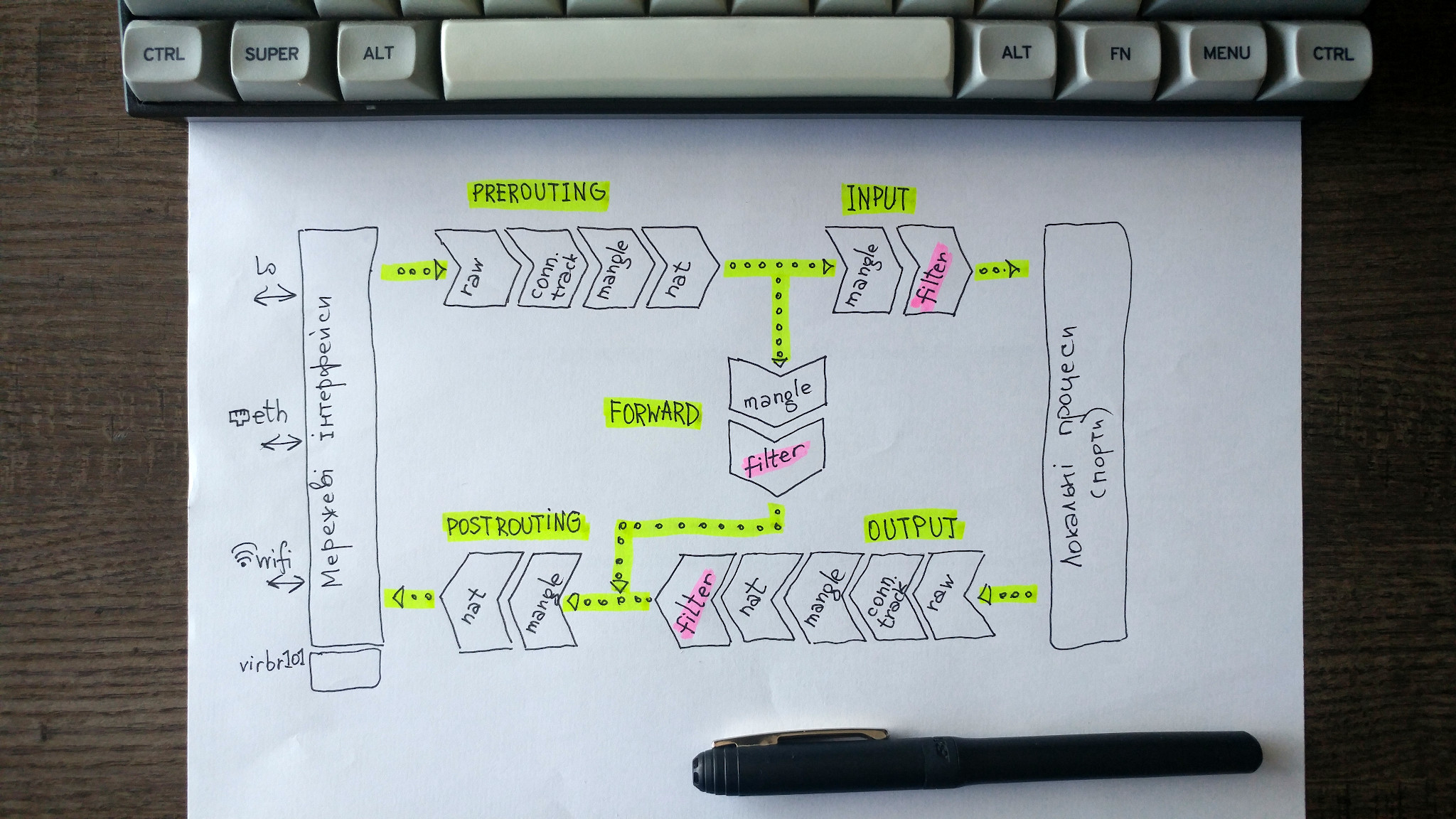
за трансляцію адрес ip (nat) відповідає, питомо, таблиця nat. найперше, забороняю nat-ування для мультикасту (224.0.0.0/24) та броадкасту (255.255.255.255/32):
#> iptables -t nat -A POSTROUTING -s 192.168.101.0/24 -d 224.0.0.0/24 -j RETURN
#> iptables -t nat -A POSTROUTING -s 192.168.101.0/24 -d 255.255.255.255/32 -j RETURN
налаштовую nat-ування для решти вихідних пакетів на всі адреси, крім віртуальної мережі (! -d 192.168.101.0/24); підказка дає три правила: для tcp, для udp і одне загальне… але хіба не достатньо одного, третього?
#> iptables -t nat -A POSTROUTING -s 192.168.101.0/24 ! -d 192.168.101.0/24 -j MASQUERADE
/i\ є різниця між snat та masquerade: перший швидший, другий універсальніший (працює з динамічним ip на зовнішньому інтерфейсі).
саме час щось випробувати — наприклад, чи працює nat-ування. скидаємо в нуль лічильники пакетів iptables для таблиці nat і перевіряємо нулики:
#> iptables -t nat -Z ; iptables -t nat -L POSTROUTING -v
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- any any 192.168.101.0/24 base-address.mcast.net/24
0 0 RETURN all -- any any 192.168.101.0/24 255.255.255.255
0 0 MASQUERADE all -- any any 192.168.101.0/24 !192.168.101.0/24
пінгуємо щось зовнішнє (приміром, google’івський dns 8.8.8.8) з адреси у віртуальній мережі (192.168.101.1):
$> ping -c 1 -I 192.168.101.1 8.8.8.8
…і перевіряємо дві речі: а) пінг проходить, і б) лічильник натованих пакетів збільшився на 1 (до речі, навіть якщо пакетів icmp пройшло більше, ніж один — спробувати -c 10 в ping’у, результат той самий; я маю розібратися, чому):
#> iptables -t nat -L POSTROUTING -v
Chain POSTROUTING (policy ACCEPT 7 packets, 758 bytes)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- any any 192.168.101.0/24 base-address.mcast.net/24
0 0 RETURN all -- any any 192.168.101.0/24 255.255.255.255
1 84 MASQUERADE all -- any any 192.168.101.0/24 !192.168.101.0/24
якщо завчасу запустити tcpdump (в сусідньому терміналі) на зовнішньому інтерфейсі сервера (enp3s0), можна побачити цей nat-ований пакет і відповідь:
#> sudo tcpdump -nn -v -i enp3s0 icmp
tcpdump: listening on enp3s0, link-type EN10MB (Ethernet), capture size 262144 bytes
15:53:05.305188 IP (tos 0x0, ttl 64, id 20676, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.1.6 > 8.8.8.8: ICMP echo request, id 9271, seq 1, length 64
15:53:05.308152 IP (tos 0x0, ttl 118, id 0, offset 0, flags [none], proto ICMP (1), length 84)
8.8.8.8 > 192.168.1.6: ICMP echo reply, id 9271, seq 1, length 64
/i\ справді, лише перший пакет icmp «клікає» лічильник nat-ованих пакетів iptables…
1.2.5. фільтрація трафіка між віртуальною та фізичною мережами за допомогою iptables
налаштовую фільтрацію пакетів (це опційно для домашнього тестлабу, ізольваного від злих хакерів домашнім шлюзом) між віртуальною (virbr101, 192.168.101.0/24) і зовнішньою (домашньою) мережами:
## дозволити вхідний трафік за встановленими підключеннями
#> iptables -t filter -A FORWARD -d 192.168.101.0/24 -o virbr101 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
## дозволити весь вихідний трафік для мережі 192.168.101.0/24
#> iptables -t filter -A FORWARD -s 192.168.101.0/24 -i virbr101 -j ACCEPT
## дозволити весь трафік між віртуальними машинами
#> iptables -t filter -A FORWARD -i virbr101 -o vrbr101 -j ACCEPT
## заборонити все інше з/до віртуальної мережі
#> iptables -t filter -A FORWARD -i virbr101 -j REJECT
#> iptables -t filter -A FORWARD -o virbr101 -j REJECT
/i\ мені здається, що обмежувати все настільки сильно (лише одна мережа 192.168.101.0/24 на віртуальному мості) — зайве для тестлабу: складніше розбиратися, якщо коли щось піде не так… я би спробував зробити простіше, помінявши порядок для надійности (але поки що залишу варіант за підказкою вище):
## дозволити весь внутрішній трафік у віртуальній мережі
#> iptables -t filter -A FORWARD -i virbr101 -o virbr101 -j ACCEPT
## дозволити вхідний трафік за встановленими підключеннями
#> iptables -t filter -A FORWARD -o virbr101 -m conntrack --ctstate RELATED, ESTABLISHED -j ACCEPT
## дозволити весь (!) вихідний трафік
#> iptables -t filter -A FORWARD -i virbr101 -j ACCEPT
## заборонити весь неврахований вхідний трафік
#> iptables -t filter -A FORWARD -i virbr101 -j REJECT
перевірка:
#> iptables -t nat -L -v
#> iptables -t filter -L -v
якщо щось пішло не так — скинути і переробити:
#> iptables -t nat -F
#> iptables -t filter -F
1.2.6. персистентна конфігурація iptables
все це прекрасно, але налаштування iptables «живуть» до перезавантаження сервера. найпростіший спосіб для debian — встановити iptables-persistent і зберегти налаштовані правила до файлу /etc/iptables/rules.v4 (для ipv4) за допомогою iptables-save:
#> apt-get install iptables-persistent
...
#> iptables-save > /etc/iptables/rules.v4
/i\ на centos 6 робиться інакше.
друга команда працює від root’а, але для sudo треба інакше:
$> sudo sh -c 'iptables-save > /etc/iptables/rules.v4'
тепер після перезавантаження — всі правила на місці.
далі підказка радить опційно запустити dhcp та dns (dnsmasq) для віртуальної мережі — але я навмивно цього не робитиму: обидва сервіси є в задачнику (див. задачу 3). також поки що не морочитимуся із прокиданням портів до віртуальних машин. тож… на цому етапі гіпервізор з віртуальною мережею має бути готовий.
1.3. керування гіпервізором
1.3.1. спроба встановлення віртуальної машини
спробую запустити віртуалку за підказкою, починаючи з кроку 4.
найперше — знайти поточний образ centos 7 замість згаданого у підказці. далі — завантажую до /var/lib/libvirt/boot/:
#> cd /var/lib/libvirt/boot/
#> wget wget https://mirrors.edge.kernel.org/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-2003.iso
спробую встановити:
#> virt-install \
--virt-type=kvm \
--name centos7 \
--ram 2048 \
--vcpus=1 \
--os-variant=rhel7 \
--hvm \
--cdrom=/var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso \
--network bridge=virbr101,model=virtio \
--nographics \
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=16,bus=virtio,format=qcow2
отримую помилку:
ERROR Couldn't create storage volume 'centos7.qcow2': 'internal error: creation of non-raw file images is not supported without qemu-img.'
гаразд, принаймні зрозуміло, чого бракує: qemu-img (з пакунка qemu-utils) для підтримки формату qcow2 (детальніше про форати вже бачив у «kvm virtualization cookbook»):
#> apt-get install qemu-utils
пробую ще раз — отримую, серед іншого, попередження:
WARNING CDROM media does not print to the text console by default, so you likely will not see text install output. You might want to use --location. See the man page for examples of using --location with CDROM media
…і, як обіцяли, отримую мовчазну консоль після такого:
Starting install...
Allocating 'centos7.qcow2' | 16 GB 00:00:03
Connected to domain centos7
Escape character is ^]
/!\ що відбувається? встановлення з локального образу iso, підключеного як оптичний диск (--cdrom=...), не підтримує вивід в текстову консоль. што?! в тенетах пишуть, що можна спробувати --location і шлях до локального файлу (або навіть до образу онлайн) як альтернативний метод, і що це працює для centos 7.
але спершу треба «прибрати сміття». підглядаю, чи невдало створена віртуалка centos7 ще крутиться:
$> virsh --connect qemu:///system list --all
Id Name State
--------------------------
- centos7 shut off
підглядаю (якщо забув), в якім файлі вона зберігається:
$> virsh --connect qemu:///system dumpxml --domain centos7 | grep 'source file'
<source file='/var/lib/libvirt/images/centos7.qcow2'/>
в моєму випадку машину зупинено, але якби крутилася — довелося б зупинити (чемно — командою shutdown, примусово — destroy):
$> virsh --connect qemu:///system destroy centos7
коли віртуалка shut off, видаляю:
$> virsh --connect qemu:///system undefine centos7
Domain centos7 has been undefined
залишиться прибрати файл centos7.qcow2 з теки /var/li/libvirt/images/, але я спробую зараз перевикористати його для нової спроби, з –location:
#> virt-install \
--virt-type=kvm \
--name centos7 \
--ram 2048 \
--vcpus=1 \
--os-variant=rhel7 \
--hvm \
--location=/var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso \
--network bridge=virbr101,model=virtio \
--nographics \
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=16,bus=virtio,format=qcow2
і отримую ще одне попередження:
WARNING Did not find 'console=ttyS0' in --extra-args, which is likely required to see text install output from the guest.
гуглю, знаходжу згадки про --extra-arguments console=ttyS0 для перенаправлення текстового виводу, з поясненням щодо недоступности параметра для джерела --cdrom. зупиняю, видаляю, пробую ще раз:
#> virt-install \
--virt-type=kvm \
--name centos7 \
--ram 2048 \
--vcpus=1 \
--os-variant=rhel7 \
--hvm \
--location=/var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso \
--network bridge=virbr101,model=virtio \
--nographics \
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=16,bus=virtio,format=qcow2 \
--extra-args console=ttyS0
нарешті, цього разу анаконда жере мою консоль! отримую текстовий інсталятор centos в консолі!
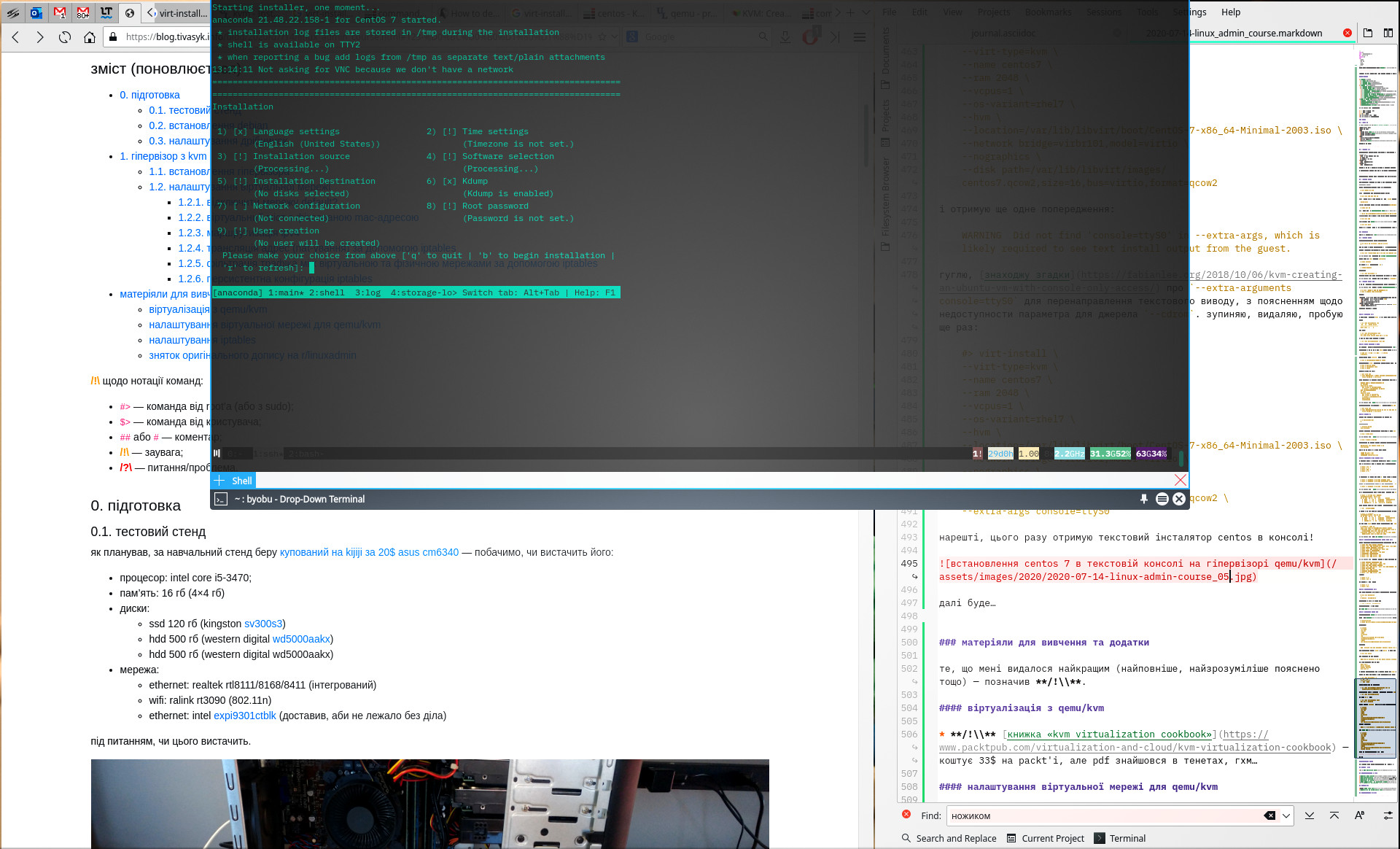
продовжую:
- налаштування мережі:
- інтерфейс: eth0;
- ім’я вузла (hostname): vm0;
- адреса ip: 192.168.101.100 (маска 255.255.255.0);
- шлюз (gateway): 192.168.101.1 (адреса севера roku на мості
virbr101); - сервери dns: 8.8.8.8,8.8.4.4 (google для простоти).
- (віртуальний) диск для встановлення:
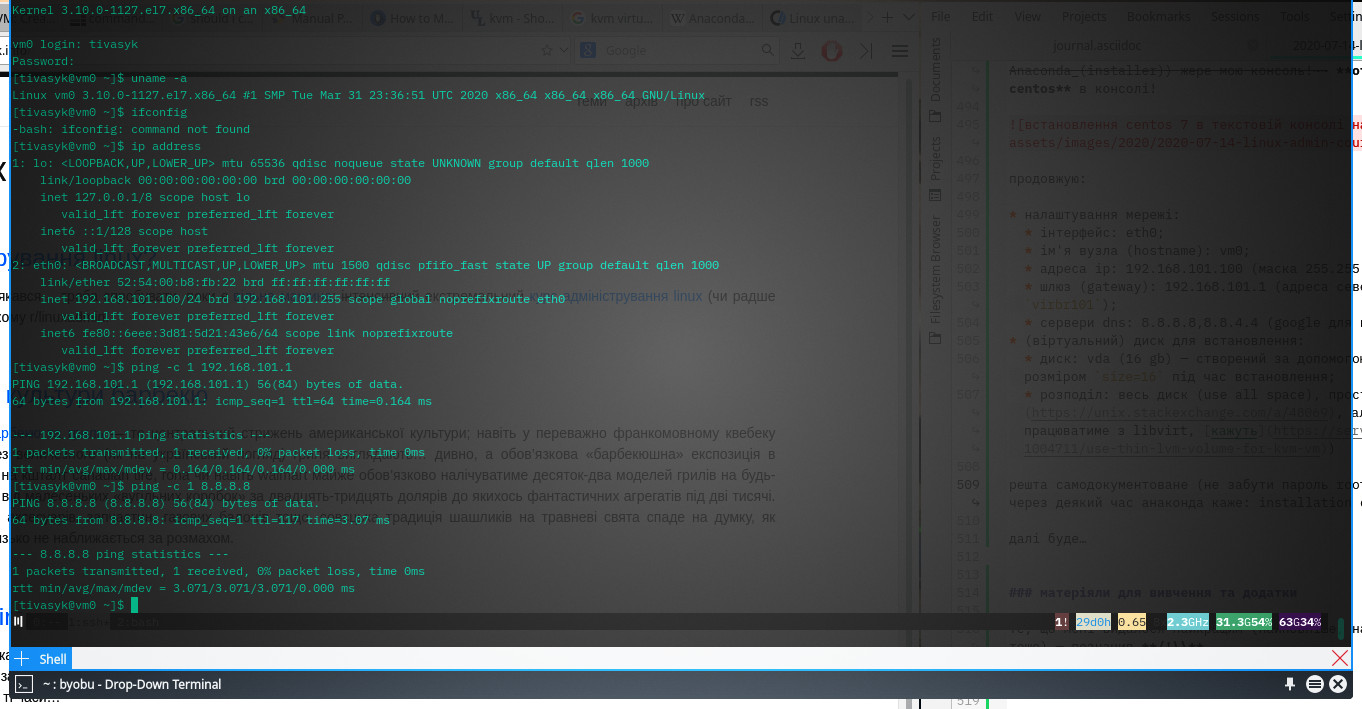
решта самодокументоване (не забути пароль root’а і додати користувача). через деякий час анаконда каже: installation complete, і після перезавантаження віртуалки бачу запрошення залогінитися.
перевірки:
$> uname -a
$> ip address
$> ping -c 1 8.8.8.8
…і, нарешті, з сервера roku (мій сервер віртуалізації) логінюся до vm0 (192.168.101.100) по ssh — все працює. зупиняю тестову віртуалку, щоби звільнити ресурси:
$> virsh --connect qemu:///system shutdown centos7
на цьому перший пункт задачника з адміністрування linux виконано: гіпервізор qemu/kvm встановлено й налаштовано.
1.3.2. аварія: випадково видалив віртуальну машину
/!\ сьогодні моя звичка друкувати швидко позбиткувалася з мене: видаляючи вчергове тестову віртуальну машину, замість vm3 надрукував… vm2:
roku #> virsh --connect qemu:///system undefine vm2
на vm2 в мене вже був сервер dhcp/dns… що робити?
на щастя, машина крутилася в цей час (зупинена була третя, а видалив визначення другої) — і продовжила крутитися, просто з persistent вона стала transient; такі машини існують до зупинки, або до перезавантаження сервера віртуалізації. машину можна відновити, якщо експортувати визначення (xml), поки вона не зупинилася:
roku #> virsh --connect qemu:///system dumpxml vm2 > /tmp/vm2.xml
roku #> virsh --connect qemu:///system define /tmp/vm2.xml
перевірка: машина повинна з’явитися у переліку персистентних:
roku #> virsh --connect qemu:///system list --all --persistent
опційно: не забути видалити vm2.xml у тимчасовій теці.
2. сервер spacewalk
задача: «2. inside of that kvm hypervisor, install a spacewalk server. use centOS 6 as the distro for all work below. (for bonus points, set up errata importation on the centos channels, so you can properly see security update advisory information)» (r/linuxadmin)
/i\ проект spacewalk зупинено в травні 2020, а centos 6 застарів (реліз 2011, підтримка лише до листопада 2020). але я принаймні спробую встановити згадані в задачнику версії; якщо ж не вийде — оберу новіший дистрибутив і якийсь інший інструмент автоматичного конфігурування для linux.
2.1. встановлення centos 6
мінімальні системні вимоги для сервера spacewalk (за документацією):
- оперативна пам’ять 2 гб;
- дисковий простір — 27 гб (округлюю до 30 гб):
- система — 3 гб (3× мінімум для centos 6)
- база данних ― 9 гб (3×1 гб на типовий «канал», 20×250 кб на клієнтську машину)
- сховище пакунків — 15 гб (3× мінімум для типового каналу redhat/centos)
/i\ в задачнику згадано 21 віртуальну машину, включаючи сервер spacewalk; здається, треба завчасу думати про 32 гб оперативної пам’яті на тестовому сервері…
шукаю й завантажую мінімальний образ centos 6 (на roku):
#> cd /var/lib/libvirt/boot/
#> wget https://mirrors.edge.kernel.org/centos/6/isos/x86_64/CentOS-6.10-x86_64-minimal.iso
встановлюю centos 6 як vm1 з диском 30 гб у файлі vm1.qcow2:
#> virt-install \
--virt-type=kvm \
--name vm1 \
--ram 2048 \
--vcpus=1 \
--os-variant=rhel6 \
--hvm \
--nographics \
--location=/var/lib/libvirt/boot/CentOS-6.10-x86_64-minimal.iso \
--network bridge=virbr101,model=virtio \
--disk path=/var/lib/libvirt/images/vm1.qcow2,size=30,bus=virtio,format=qcow2 \
--extra-args console=ttyS0
інсталятор centos 6 не додає користувача (лише root) і не намагається налаштувати мережу… тож після перезавантаження доведеться «допиляти напилком» — тому не закриваю консоль і логінюся root’ом; найперше, мережа…
міняю hostname на vm1.lab (омфг, чому я не вивчив vi? в мінімальному centos 6 немає nano) у файлі /etc/sysconfig/network:
HOSTNAME=vm1.lab
перевіряю, що з мережевими інтерфейсами — маю eth0, але не налаштований, без адреси:
#> ip address
ремонтую, редагуючи файл /etc/sysconfig/network-scripts/ifcfg-eth0 (ключові поля — onboot=yes і далі):
DEVICE=eth0
HWADDR=52:54:00:7A:DA:A1
TYPE=Ethernet
UUID=a64b72f6-4736-4faa-9dc8-e4c422d727f2
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=none
IPADDR=192.168.101.101
PREFIX=24
GATEWAY=192.168.101.1
NAME="System eth0"
«пересмикую» мережевий сервіс:
#> service network restart
додаю гуглівські сервери dns та (опційно) локальний домен (lab) до /etc/resolv.conf:
domain lab
search lab
nameserver 8.8.8.8
nameserver 8.8.4.4
перевіряю, чи спрацювало (чи встановлено ip, чи пінгується шлюз (roku) і чи працює визначення доменних імен з гуглівськими dns’ами):
#> ip address
#> ping 192.168.101.1
#> ping google.com
все працює.
/i\ здається, конфігурацію dns та домену можна помістити а) до /etc/sysconfig/network-scripts/ifcfg-eth0, б) до /etc/sysconfig/network або до в) /etc/resolv.conf. хз, як найкраще; залишив те, що вже працює.
поновлюю систему:
#> yum update
створюю собі користувача (tivasyk), додаю до групи wheel, і розкоментовую рядок %wheel ALL=(ALL) ALL в /etc/sudoers (канонічно — за допомогою visudo), щоби отримати шаманський бубен доступ до sudo:
#> adduser tivasyk
#> passwd tivasyk
#> usermod -aG wheel tivasyk
#> visudo
логінюсь із roku по ssh до нової віртуальної машини (192.168.101.101) як tivasyk, щоби перевірити, чи працює. перезавантажую віртуалку (суто заради доменного імені):
#> reboot
машина готова для спроби встановлення spacewalk.
2.2. встановлення spacewalk
2.2.1. перша спроба — гучний пшик!
за підказкою, додаю репозиторій spacewalk на щойно встановленій centos 6 (не переплутати версії системи, кутузов!):
vm1 #> yum install -y yum-plugin-tmprepo
vm1 #> yum install -y spacewalk-repo --tmprepo=https://copr-be.cloud.fedoraproject.org/results/%40spacewalkproject/spacewalk-2.10/epel-6-x86_64/repodata/repomd.xml --nogpg
встновлюю додаткові пакунки epel заради java (тільки якого біса підказка робить це за допомогою rmp, якщо канонічний шлях — yum?):
## rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm (краще за допомогою yum:)
vm1 #> yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm
за базу даних для spacewalk обираю найпростіший варіант — сервер postgresql, запакований спеціяльно для spacewalk:
vm1 #> yum -y install spacewalk-setup-postgresql
нарешті, пробую встановити власне сам spacewalk:
vm1 #> yum -y install spacewalk-postresql
тут centos на кільканадцять хвилин перемикається в режим пилосмока і затягує/встановлює купу всякого сміття (458 пакунків)… аж поки звітує: complete!
обов’язкове налаштування мережевого екрану (в тестлабі на roku все відкрито, але на віртуальній машині з centos все закрито «з коробки»). centos 6 використовує iptables (а пізніші версії — firewalld).
перевірка того, що вже є (--line-numbers додає номери):
vm1 #> iptables -t filter -L INPUT -v
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 935 43462 ACCEPT all -- any any anywhere anywhere state RELATED,ESTABLISHED
2 0 0 ACCEPT icmp -- any any anywhere anywhere
3 687 41218 ACCEPT all -- lo any anywhere anywhere
4 0 0 ACCEPT tcp -- any any anywhere anywhere state NEW tcp dpt:ssh
5 0 0 REJECT all -- any any anywhere anywhere reject-with icmp-host-prohibited
для простоти можна було би видалити останнє правило (reject), але потреную навичку iptables, встромивши кілька правил перед останнім:
vm1 #> iptables -t filter -I INPUT 5 -p tcp --dport 80 -j ACCEPT
vm1 #> iptables -t filter -I INPUT 6 -p tcp --dport 443 -j ACCEPT
vm1 #> iptables -t filter -I INPUT 7 -p tcp --dport 5222 -j ACCEPT
vm1 #> iptables -t filter -I INPUT 8 -p udp --dport 69 -j ACCEPT
зберігаю зміни, щоби все було на місці після перезавантаження (робиться інакше, ніж для debian):
vm1 #> service iptables save
переходжу до налаштування spacewalk. перша ж заява підказки насторожує:
Your Spacewalk server should have a resolvable fully-qualified domain name (FQDN) such as ‘hostname.domain.com’. If the installer complains that the hostname is not the FQDN, do not use the –skip-fqdn-test flag to skip !
а от доменного імені віртуалка й не має: я використав гуглівський dns для налаштування мережі, котрий, звісно ж, не знає ні про який vm1.lab. пробую, тим не менш:
vm1 #> spacewalk-setup
…і все закінчується помилкою:
Tomcat failed to start properly or the installer ran out of tries. Please check /var/log/tomcat6/catalina.out or /var/log/tomcat/catalina.$(date +%Y-%m-%d).log for errors.
здається, таки проблема у доменному імені (за звітом у /var/log/tomcat6/catalina.out):
2020-08-21 16:39:27,717 [main] ERROR net.sf.ehcache.Cache - Unable to set localhost. This prevents creation of a GUID. Cause was: vm1.lab: vm1.lab: Name or service not known
...
/!\ схоже, сервер dns в тестлабі знадобиться раніше за spacewalk — попри те, що в задачнику йде наступним пунктом. але ще погуглю трішки, перш ніж здаватися… як спроба надурити того котяру tomcat’а — додаю дещо до /etc/hosts:
127.0.1.1 vm1 vm1.lab
192.168.101.101 vm1 vm1.lab
тоді пробую ще раз, пропускаючи етап створення бази даних postgresql (бо інакше інсталятор сваритиметься):
vm1 #> spacewalk-setup --skip-db-install
/!\ знову помилка, але цього разу дещо інша:
Could not deploy SSL certificate. Exit value: 1.
Please examine /var/log/rhn/rhn_installation.log for more information.
/!\ трохи потряс бубном (видалив пакунок rhn-org-httpd-ssl-key-pair-vm1.lab-1.0-1.noarch, на який скаржився конфігуратор), пробую ще раз — знову помилка tomcat6/catalina, але цього разу інша:
Aug 24, 2020 8:52:02 AM org.apache.catalina.loader.WebappClassLoader clearThreadLocalMap
SEVERE: A web application created a ThreadLocal with key of type [null] (value [com.redhat.rhn.common.hibernate.ConnectionManager$1@4a7fd0c9]) and a value of type [null] (value [null]) but failed to remove it when the web application was stopped. To prevent a memory leak, the ThreadLocal has been forcibly removed.
Aug 24, 2020 8:52:03 AM org.apache.coyote.http11.Http11Protocol destroy
INFO: Stopping Coyote HTTP/1.1 on http-127.0.0.1-8080
/!\ після цього сам сервіс spacewalk крутиться, але веб-сервер (httpd) — ні…
/usr/sbin/spacewalk-service status
postmaster (pid 4244) is running...
router (pid 4275) is running...
sm (pid 4283) is running...
c2s (pid 4291) is running...
s2s (pid 4299) is running...
tomcat6 (pid 4359) is running... [ OK ]
httpd is stopped
osa-dispatcher dead but pid file exists
rhn-search is running (4537).
cobblerd (pid 4576) is running...
RHN Taskomatic is running (4603).
журнал каже, що йому бракує сертифікату spacewalk.crt, котрий я (баранисько) випадково видалив (не зберігши резервної копії) на попередньому етапі, намагаючись налаштувати spacewalk…
2.2.2. друга спроба
поки я ще відносно недалеко заблукав у нетрях, починаю встановлення сервера spacewalk від початку. зупиняю і видаляю віртуальну машину vm1, залишаючи файл vm1.qcow2:
roku #> virsh --connect qemu:///system destroy vm1
roku #> virsh --connect qemu:///system undefine vm1
далі за вже знайомою схемою:
- перестворюю віртуальну машину
vm1і встановлюю centos 6; - налаштовую мережу (включно з vm1.lab до файлу
/etc/hostsцього разу), користувача, тощо; поновлюю систему; - додаю необхідні репозиторії spacewalk;
- встановлюю postgresql для spacewalk;
- встановлюю spacewalk;
- момент істини: запускаю конфігуратор
spacewalk-setup…
…і цього разу отримую:
Installation complete.
Visit https://vm1 to create the Spacewalk administrator account.
2.2.3. доступ до веб-інтерфейсу spacewalk
невеличка проблема в тому, що всередині тестлаба я не маю жодної машини з графічним інтерфейсом… як варіант — можу спробувати перенаправити запити на порти 80 (http) та 443 (https) зовнішнього мережевого інтерфейсу roku (192.168.1.6) до відповідних портів віртуальної машини vm1 (192.168.101.101):
roku #> iptables -t nat -A PREROUTING -d 192.168.1.6/32 -p tcp -m tcp --syn -m multiport --dports 80,443 -j DNAT --to-destination 192.168.101.101
заразом додам переадресацію порту 10122 до порту 22 віртуалки (ssh), щоби підключатся напряму (до цього підключався спершу до roku, а звідти — до віртуалки):
roku #> iptables -t nat -A PREROUTING -d 192.168.1.6/32 -p tcp -m tcp --syn --dport 10122 -j DNAT --to-destination 192.168.101.101:22
/i\ ще раз перевірити налаштування iptables на віртуалці vm1, бо centos «із коробки» досить закритий, як і личить корпоративному дистрибутиву на базі red hat.
і ось вона, магія шаманського бубна: https://192.168.1.6 в домашній мережі відповідає запрошенням spacewalk від щойно встановленої віртуалки vm1, з пропозицією налаштувати першого користувача.
2.3. налаштування spacewalk
найперше, як запропоновано — налаштовую користувача, котрий буде адміністратором spacewalk (тут головне — не забути пароль).
2.3.1. канали програмного забезпечення
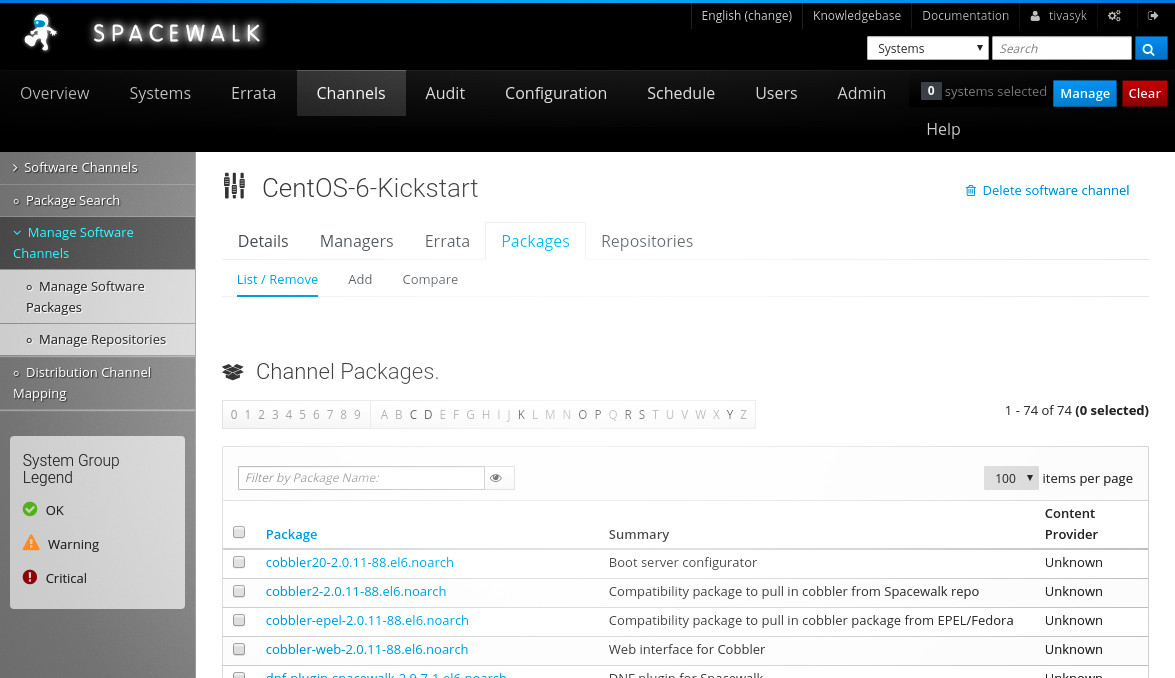
далі, — за підказкою, — додаю два канали, і до кожного — основні репозиторії centos відповідної версії:
- канал centos-6-parent
- репо centos-6-os
- репо centos-6-extras
- репо centos-6-updates
- канал centos-7-parent
- репо centos-7-os
- репо centos-7-extras
- репо centos-7-updates
синхронізація репозиторіїв займає чимало часу; я, на жаль, запустив її з веб-інтерфейсу, і згодом намагався слідкувати, переглядаючи журнали (замість tail -F інколи зручніше less +G) — дуже дуже інформативно:
vm1 #> tail -F /var/log/rhn/reposync.log
vm1 #> tail -F /var/log/rhn/reposync/centos-7-parent.log
варто було для першої синхронізації скористатися консольним інструментом spacewalk-repo-sync. втім, рано чи пізно синхронізація закінчується, і spacewalk показує вміст каналів.
/!\ тут виявилося, що 30 гб на диску під spacewalk було замало: канали пакунків відмовляються синхронізуватися, неможливо створити канал конфігурації, ба навіть встановити невеличкий додатковий інструмент (spacecmd) не вдалося через брак місця на диску:
vm1 #> sudo yum install spacecmd
...
Total download size: 246 k
Installed size: 1.2 M
Is this ok [y/N]: y
Downloading Packages:
Error Downloading Packages:
spacecmd-2.10.5-1.el6.noarch: Insufficient space in download directory /var/cache/yum/x86_64/6/spacewalk/packages
* free 0
* needed 246 k
після перезавантаження postgresql звітує, що не може запуститися:
vm1 #> service postgresql status
postmaster is stopped
df каже, що диск заповнений на 100%:
vm1 #> df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root
26G 26G 0 100% /
немає бази даних — не працює spacewalk, веб-інтерфейс, неможливо коректно видалити ані канал, ані завантажені пакунки, щоби звільнити трохи місця… дупа. перш ніж рухатися далі, час навчитися збільшувати розділи в файлах віртуальних машин.
2.3.2. збільшення дискового простору для віртуальної машини
по-перше, зупиняю vm1 (по-хорошому не хоче, зупинимо примусово):
roku $> virsh --connect qemu:///system destroy vm1 && virsh --connect qemu:///system list --all
для надійності — перевіряю, які файли образів використовує libvirt для віртуальної машини:
roku $> virsh --connect qemu:///system domblklist vm1
Target Source
---------------------------------------------
vda /var/lib/libvirt/images/vm1.qcow2
hda -
інформація про файл vm1.qcow2:
roku #> qemu-img info /var/lib/libvirt/images/vm1.qcow2
трохи навчений, зберігаю копію образу vm1 (операція займає трохи часу):
roku #> cp /var/lib/libvirt/images/vm1.qcow2 /var/lib/libvirt/images/vm1.qcow2.bak
пробую збільшити розмір файлу (virtual size) qcow2 на 70 гб за допомогою qemu-img:
roku $> qemu-img resize /var/lig/libvirt/images/vm1.qcow2 +70G
на жаль, це лише початок. далі запускаю vm1 і перевіряю розмір віртуального диска (vda) — тепер 100 гб:
roku $> virsh --connect qemu:///system start vm1
roku $> ssh tivasyk@192.168.1.6 -p 10122
...
vm1 #> lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 100G 0 disk
├─vda1 252:1 0 500M 0 part /boot
└─vda2 252:2 0 29.5G 0 part
├─VolGroup-lv_root (dm-0) 253:0 0 26.5G 0 lvm /
└─VolGroup-lv_swap (dm-1) 253:1 0 3G 0 lvm [SWAP]
мене цікавить отой VolGroup-lv_root, — це логічний том lvm lv_root, який належить до групи VolGroup і який змонтовано в корінь (/) віртуальної машини. де він фізично? з виводу lsblk можна здогадатися, що в розділі /dev/vda2 (фізичний том lvm), але перевірю:
vm1 #> pvscan
PV /dev/vda2 VG VolGroup lvm2 [29.51 GiB / 0 free]
Total: 1 [29.51 GiB] / in use: 1 [29.51 GiB] / in no VG: 0 [0 ]
вгадав. детальніше про фізичний том:
vm1 #> pvdisplay /dev/vda2
розмір розділу — поки ще 29,51 гб. ще більше технічної інформації про розділ:
vm1 #> fdisk /dev/vda2
момент істини: спроба збільшити кореневий розділ віртуальної машини «на льоту» тепер за допомогою fdisk — для цього треба занотувати геометрію розділу, видалити його і перестворити на тому ж місці (first sector), але більшого розміру (last sector)…
vm1 #> fdisk /dev/vda
перелік розділів — p; занотовую переметри потрібного розділу (/dev/vda2):
Command (m for help): p
...
Device Boot Start End Blocks Id System
...
/dev/vda2 1018 62416 30944256 8e Linux LVM
видаляю (d) другий (2) розділ і створюю наново (n) як primary (p) з тим самим номером (2):
Command (m for help): d
Partition number (1-4): 2
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (1-208050, default 1): 1018
Last cylinder, +cylinders or +size{K,M,G} (1018-208050, default 208050):
Using default value 208050
записую зміни на диск (w); fdisk попереджає про те, що ядро далі використовує застарілу копію таблиці розділів, і треба його повідомити про зміни. найпростіше — перезавантажитися. знову перевіряю, що каже lsblk про накопичувачі:
vm1 #> lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 100G 0 disk
├─vda1 252:1 0 500M 0 part /boot
└─vda2 252:2 0 99.5G 0 part
├─VolGroup-lv_root (dm-0) 253:0 0 26.5G 0 lvm /
└─VolGroup-lv_swap (dm-1) 253:1 0 3G 0 lvm [SWAP]
розмір розділу /dev/vda2 тепер — 99,5 гб. але фізичний том lvm не збільшується автоматично (перевірка pvscan) — збільшую примусово:
vm1 #> pvresize /dev/vda2
і перевіряю:
vm1 #> pvscan
PV /dev/vda2 VG VolGroup lvm2 [99.51 GiB / 70.00 GiB free]
Total: 1 [99.51 GiB] / in use: 1 [99.51 GiB] / in no VG: 0 [0 ]
група lvm автоматично збільшується разом з відповідним фізичним томом (перевірка vgdisplay). на черзі — збільшити розмір логічного тома lv_root так, щоби зайняти все вільне місце на фізичному томі (-l +100%FREE):
vm1 #> lvresize -l +100%FREE VolGroup/lv_root
Size of logical volume VolGroup/lv_root changed from 26.50 GiB (17920 extents) to 96.51 GiB (24706 extents).
Logical volume lv_root successfully resized.
залишилося тільки збільшити розмір файлової системи на логічному томі (бо я забув спробувати ключик -r для lvresize)…
vm1 #> resize2fs /dev/mapper/VolGroup-lv_root
підсумкова перевірка:
vm1 #> lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 100G 0 disk
├─vda1 252:1 0 500M 0 part /boot
└─vda2 252:2 0 99.5G 0 part
├─VolGroup-lv_root (dm-0) 253:0 0 96.5G 0 lvm /
└─VolGroup-lv_swap (dm-1) 253:1 0 3G 0 lvm [SWAP]
...
vm1 #> df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root
95G 26G 65G 29% /
перезапускаю машину, тримаючи кулаки, щоби все «піднялося»… здається, вдалося: веб-інтерфейс spacewalk знову працює.
/i\ не забути прибрати копію образу віртуальної машини (vm1.qcow2.bak), щоби не займала намарне місця:
vm1 #> rm /var/lib/libvirt/images/vm1.qcow2.bak
2.3.3. spacecmd — керування сервером spacewalk з командного рядка
гадаю, цей інструмент знадобиться згодом, щоби не пацькати руки щоразу веб-інтерфейсом (на centos 6 без python-argparse лається і не працює):
vm1 #> yum install spacecmd python-argparse
перевірка, чи працює (перший раз потребує автентифікації, зберігає логін та хеш пароля до ~/.spacecmd/vm1.lab/session):
vm1 $> spacecmd softwarechannel_list
INFO: Connected to https://vm1.lab/rpc/api as tivasyk
centos6
2.4. бонус: імпорт errata для centos до spacewalk
найперше — встановлюю wget на сервері spacewalk (здивований, що мінімальний centos 6 іде без цієї перлини):
vm1 #> yum -y install wget
завантажую розумний perl-скрипт errata-import.pl від стіва мейєра:
vm1 #> wget https://github.com/stevemeier/cefs/raw/master/errata-import.pl
через веб-інтерфейс створюю користувача errata з простим паролем (qwerty згодиться) спеціяльно для скрипта; в налаштуваннях цьому користувачеві треба призначити роль «channel administrator».
/i\ знадобиться довстановити ще дещо із залежностей скрипта:
vm1 #> yum -y install perl-Frontier-RPC perl-Text-Unidecode perl-XML-Simple
пробний запуск:
vm1 #> env -i SPACEWALK_USER=errata SPACEWALK_PASS='qwerty' /root/bin/errata-import.pl --server localhost --errata errata.latest.xml --publish
/!\ …i отримую помилку: ERROR: errata.latest.xml is not an errata file! — само собою, я щось не врахував; перечитую ще раз (скупу) підказку з використання скрипта, і здогадуюсь: файл errata треба завантажувати окремо!
vm1 #> wget -N -O /root/errata.latest.xml https://cefs.steve-meier.de/errata.latest.xml
vm1 #> env -i SPACEWALK_USER=errata SPACEWALK_PASS='qwerty' /root/errata-import.pl --server localhost --errata /root/errata.latest.xml --publish
/i\ wget потребує опції -O, щоби примусово перезаписати файл errata.latest.xml, якщо вже існує (інакше створить копію, додавши .1, .2 тощо до назви); ключ -N змушує завантажувати лише поновлений файл повідомлень (менший трафік).
наприкінці скрипт звітує про помилку 500 read timeout (розібратися згодом?), але головне: веб-інтерфейс тепер показує перелік повідомлень про поновлення пз.
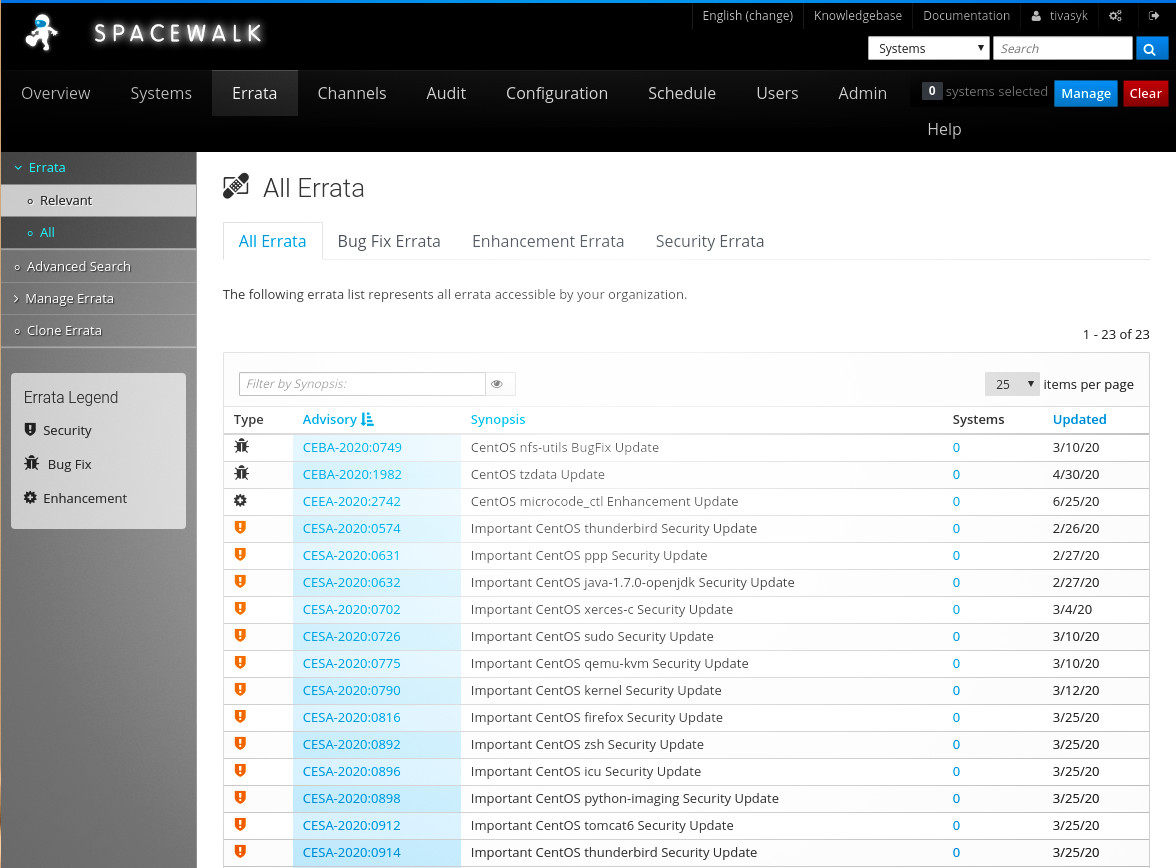
залишилося автоматизувати періодичне (що п’ятниці о 23:00) поновлення цих повідомлень за допомогою crontab -e (і, опційно, звіт до /var/log/messages):
23 0 * * 5 wget -N -O /root/errata.latest.xml https://cefs.steve-meier.de/errata.latest.xml && env -i SPACEWALK_USER=errata SPACEWALK_PASS='qwerty' /root/errata-import.pl --server localhost --errata /root/errata.latest.xml --publish && logger "CentOS errata imported to Spacewalk (maybe)"
перевірка планувальника:
vm1 #> crontab -l
на цьому другий пункт задачника виконано.
3. сервер dhcp/dns
цитата: «create a vm to provide named and dhcpd service to your entire environment. set up the dhcp daemon to use the spacewalk server as the pxeboot machine (thus allowing you to use cobbler to do unattended os installs). make sure that every forward zone you create has a reverse zone associated with it. use something like “internal.virtnet” (but not “.local”) as your internal dns zone» (r/linuxadmin)
3.1. віртуальна машина vm2
основні параметри для віртуального сервера dhcp/dns на centos 6 (на основі мінімальних системних вимог):
- оперативна пам’ять: 1 гб (згодом можна додати або відняти);
- дисковий простір: 10 гб (мінімум 5 гб).
образ для встановлення вже завантажено; створюю нову віртуалку (vm2):
roku #> virt-install \
--virt-type=kvm \
--name vm2 \
--ram 1024 \
--vcpus=1 \
--os-variant=rhel6 \
--hvm \
--nographics \
--location=/var/lib/libvirt/boot/CentOS-6.10-x86_64-minimal.iso \
--network bridge=virbr101,model=virtio \
--disk path=/var/lib/libvirt/images/vm2.qcow2,size=10,bus=virtio,format=qcow2 \
--extra-args console=ttyS0
перезавантаження (поки що в консоль на roku), логін root’ом; налаштування мережі:
- назва вузла: vm2.lab;
- адреса ip: 192.168.101.102/24,
- шлюз: 192.168.101.1;
- dns: 8.8.8.8,8.8.4.4
додаю користувача tivasyk з правами sudo.
на сервері віртуалізації (roku) додаю переадресацію порту 10222 для ssh нової віртуальної машини (і зберігаю налаштування iptables):
roku #> iptables -t nat -A PREROUTING -d 192.168.1.6/32 -p tcp -m tcp --syn --dport 10222 -j DNAT --to-destination 192.168.101.102:22
roku #> iptables-save /etc/iptables/rules.v4
перевіряю підключення ssh всередині віртуальної мережі (з roku) та зі зовні (з іншої машини в зовнішній, домашній мережі).
3.2. реєстрація клієнта на сервері spacewalk
3.2.1. створення ключа активації
найперше — на сервері spacewalk (vm1) створюю загальний ключ активації, який буде загальний для всіх клієнтських машин на centos 6; замість лізти на веб-інтерфейс, зроблю за допомогою spacecmd (підказка про virtualization_host entitlement):
vm1 #> spacecmd activationkey_create
Name (blank to autogenerate): centos-6-multikey
Description [None]: CentOS 6 (x86_64) activation multikey
Base Channels
-------------
centos6
Base Channel (blank for default): centos6
virtualization_host Entitlement [y/N]: y
Universal Default [y/N]: y
INFO: Created activation key 1-centos-6-multikey
перевірка:
vm1 #> spacecmd activationkey_list
vm1 #> spacecmd activationkey_details 1-centos6-multikey
3.2.2. встановлення клієнта spacewalk
на майбутньому сервері dhcp/dns (vm2) — додаю репозиторій з клієнтом spacewalk для centos 6:
vm2 #> yum -y install https://copr-be.cloud.fedoraproject.org/archive/spacewalk/2.7-client/RHEL/6/x86_64/spacewalk-client-repo-2.7-2.el6.noarch.rpm
/i\ уважно з версіями; підказки часто дають посилання на centos 7 і не згадують шістку!
додаю репозиторій epel, встановлюю клієнт з необхідними залежностями й інструментами з epel:
vm2 #> yum -y install epel-release && yum -y update
vm2 #> yum -y install rhn-client-tools rhn-check rhn-setup rhnsd m2crypto yum-rhn-plugin
до файлу /etc/hosts додаю ім’я локального сервера spacewalk (vm1 та vm1.lab, можна з псевдонімом spacewalk та spacewalk.lab):
192.168.101.101 vm1 vm1.lab spacewalk spacewalk.lab
перевіряю, чи працює, за допомогою простого пінга:
vm2 $> ping spacewalk.lab
затягую сертифікат ssl просто з сервера spacewalk (на машині vm1 файл сертифікату й пакунок rmp можна знайти в /var/www/html/pub):
vm2 #> yum -y install http://spacewalk.lab/pub/rhn-org-trusted-ssl-cert-1.0-1.noarch.rpm
3.2.3. реєстрація на сервері spacewalk
нарешті, пробую зареєструвати клієнта на сервері spacewalk з ключем активації 1-centos-6-multikey:
vm2 #> rhnreg_ks --activationkey 1-centos-6-multikey --serverUrl https://spacewalk.lab/XMLPRC
/!\ …і отримую помилку:
An error has occurred:
rhn-plugin: Error communicating with server. The message was:
Not Found
See /var/log/up2date for more information
дивно, але я спробував явно вказати файл сертифікату (на клієнті файл лежить в /usr/share/rhn) — і vm2 зареєструвався:
vm2 #> rhnreg_ks --serverUrl=https://spacewalk.lab/XMLRPC --sslCACert=/usr/share/rhn/RHN-ORG-TRUSTED-SSL-CERT --activationkey=1-centos-6-multikey
перевірка за допомогою spacecmd:
vm1 #> spacecmd system_list
INFO: Connected to https://vm1.lab/rpc/api as tivasyk
vm2.lab : 1000010000
...
vm1 #> spacecmd system_details vm2.lab
машину vm2 тепер видно й у веб-інтерфейсі spacewalk (systems > systems > all).
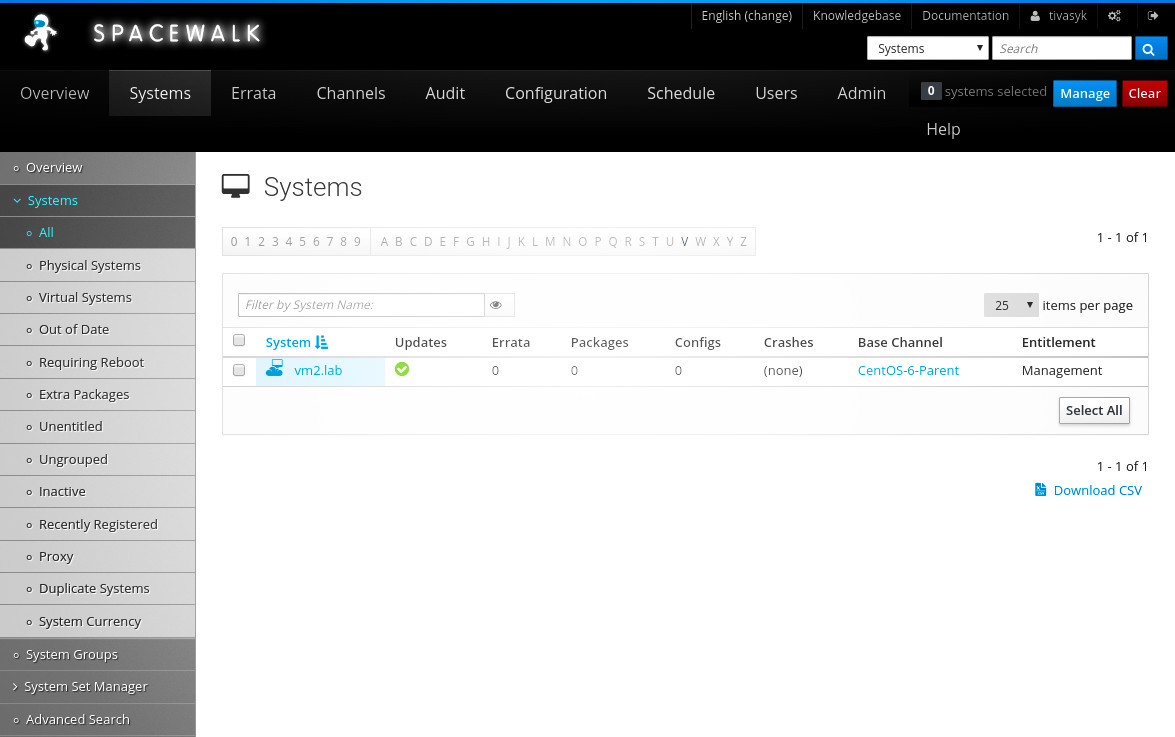
/!\ але спроба поновити репозиторії на клієнтській машині перечіпляється через помилку:
vm2 #> yum update
Loaded plugins: fastestmirror, rhnplugin
...
Error: Cannot retrieve repository metadata (repomd.xml) for repository: centos6. Please verify its path and try again
за підказкою перевіряю, чи на місці файл repomd.xml для каналу centos6 на сервері spacewalk, — все виглядає добре:
vm1 #> ls -l ls /var/cache/rhn/repodata/centos6
filelists.xml.gz other.xml.gz primary.xml.gz repomd.xml updateinfo.xml.gz
за іншою підказкою пробую відключити https на користь http для up2date на клієнті vm2 (файл /etc/sysconfig/rhn/up2date):
## serverURL=https://spacewalk.lab/XMLRPC
serverURL=http://spacewalk.lab/XMLRPC
…і поновлення працює. отже, проблема десь із ssl? перевіряю ще раз все, що стосується ssl, у файлі конфігурації up2date за підручником… чомусь бракує рядка:
noSSLserverURL=http://spacewalk.lab/XMLRPC
додаю (повернувши рядок serverURL до початкового значення з https), пробую ще раз yum update — працює. гхм.
3.3. налаштування сервера dhcp/dns на базі dnsmasq
3.3.1. встановлення dnsmasq дистанційно зі spacewalk
бачу два поширених варіанти налаштування сервісів dhcp/dns:
- bind + dhcpd — класична пара: більше можливостей, складніше налаштування;
- dnsmasq — поєднує обидва сервіси (плюс tftp, pxe, але ці мають бути в мене на сервері spacewalk), простий в налаштуванні, але має чимало обмежень.
для початку спробую простіший dnsmasq (згодом, якщо знадобиться, заміню); «з коробки» в centos 6 немає, але встановлюється елементарно:
vm2 #> yum -y install dnsmasq
але! чому не спробувати встановити дистанційно, з сервера spacewalk? через веб-інтерфейс (systems > vm2.lab > software > install) планую поновлення репозиторіїв та встановлення dnsmasq — і чекаю (за замовчуванням, клієнти «чекіняться» на сервері що дві години).
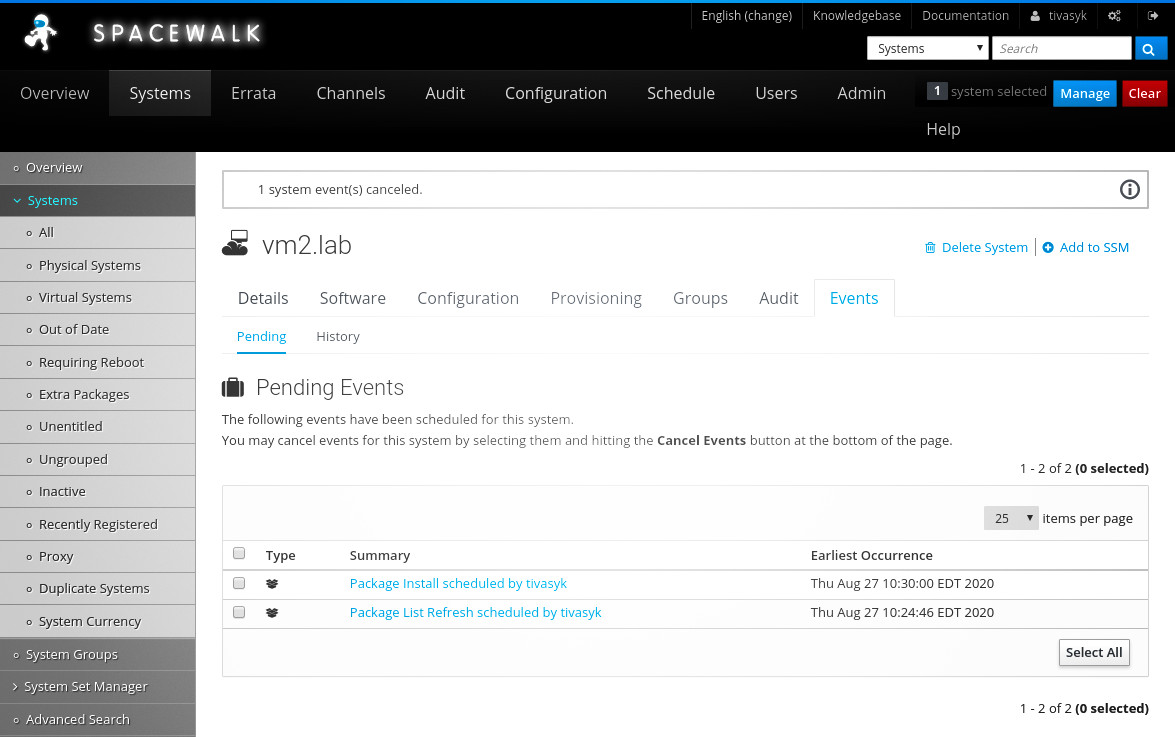
через півгодини обидві задачі опиняються в історії завдань (systems > vm2.lab > events > history) із зеленими галочками (виконано). можна братися до налаштування сервісів.
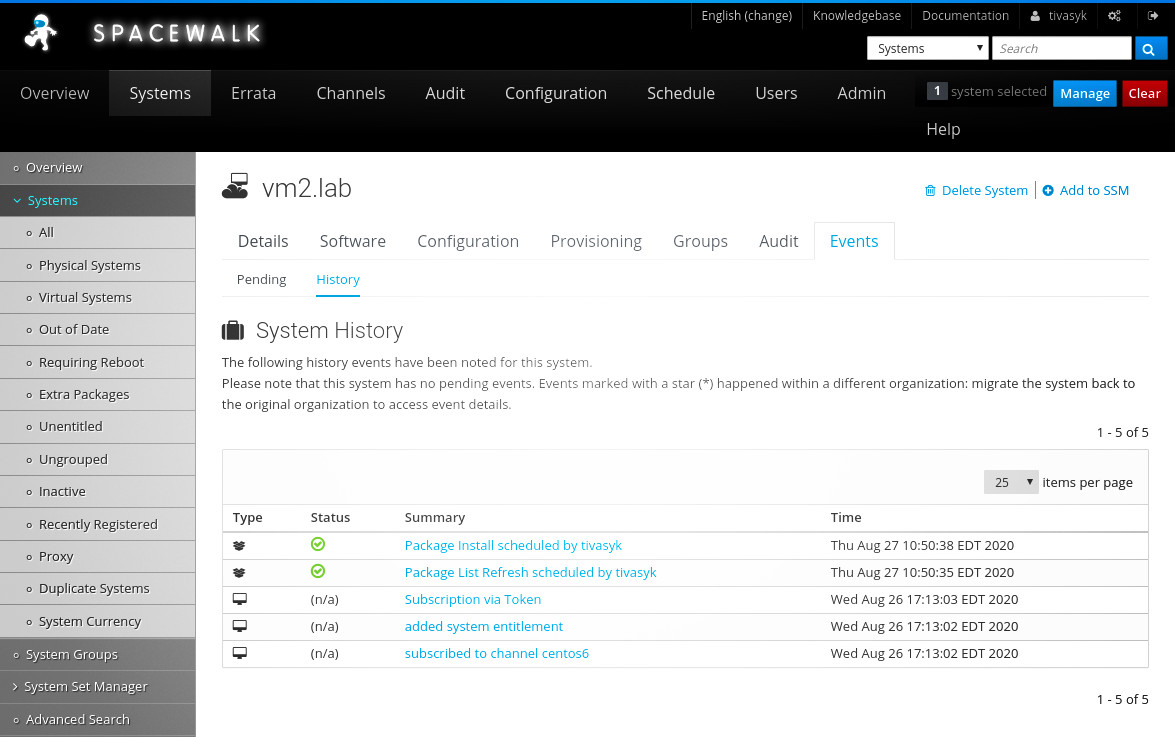
3.3.2. налаштування dns з використанням dnsmasq
копія оригінального файлу з налаштуваннями dnsmasq, на випадок «аварії»:
vm2 #> cp /etc/dnsmasq.conf /etc/dnsmasq.conf.bak
налаштування; лише декотрі з рядків у /etc/dnsmasq.conf потребують зміни:
interface=eth0
listen-adress=::1,127.0.0.1,192.168.101.102
domain=lab
local=/lab/
address=/lab/127.0.0.1
expand-hosts
no-resolv
server=8.8.8.8
server=8.8.4.4
підсумкова перевірка файлу налаштувань:
vm2 #> dnsmasq --test
dnsmasq: syntax check OK.
видаляю зовнішні dns’и з /etc/resolv.conf — там повиннен залишитися лише один рядок з dns 127.0.0.1 (та ::1 для ipv6):
nameserver 127.0.0.1
nameserver ::1
убезпечую /etc/resolv.conf від перезапису (network manager та деякі інші програми люблять таким займатися):
vm2 #> chattr +i /etc/resolv.conf
/i\ не всі файлові системи поважають прапорець -i (immutable), але ext4 серед слухняних. перевірка:
vm2 #> lsattr /etc/resolv.conf
гаразд, час запустити сервіс:
vm2 #> /etc/init.d/dnsmasq start
автозапуск на centos 6 налаштовується інакше, ніж на сучасних системах із systemd:
vm2 #> chkconfig --add dnsmasq
vm2 #> chkconfig dnsmasq on
перевірка (рівні 2-5 повинні бути on):
vm2 #> chkconfig --list | grep dnsmasq
перевіряю локально, на тій самій машині (знадобиться встановити ldns, щоби отримати доступ до drill; grep абсолютно опційний — аби скоротити вивід):
vm2 #> drill -4 google.com | grep -A1 "ANSWER SECTION"
;; ANSWER SECTION:
google.com. 42 IN A 172.217.13.110
зворотній запис (-x):
vm2 #> drill -4 -x 192.168.101.101 | grep -A1 "ANSWER SECTION"
;; ANSWER SECTION:
101.101.168.192.in-addr.arpa. 0 IN PTR vm1.lab.
dnsmasq знає про google (та всі зовнішні ресурси), бо по все, що поза доменом lab, звертається до зовнішніх dns’ів (server=8.8.8.8); він знає про імена для адреси 192.168.101.101, бо я додав їх до /etc/hosts на цій машині (vm2), коли підключав її до spacewalk… але сам себе, приміром, не прорезолвить, бо цього запису немає в /etc/hosts! отже…
/i\ мірою додавання машин (зі статичними ip) до тестлабу, треба не забувати реєструвати їх (разом із псевдонімами) до /etc/hosts на віртуалці vm2:
192.168.101.1 router router.lab
192.168.101.101 vm1 vm1.lab spacewalk spacewalk.lab
192.168.101.102 vm2 vm2.lab dns dns.lab
/i\ локальні запити працюють, — але для запитів з інших машин потрібно відкрити порт 53 (dns) для протоколів tcp і udp (dns може використовувати обидва) на vm2. мене цікавить лише таблиця input (бо вихідна — відкрита на centos 6):
vm2 #> iptables -t filer -L INPUT --line-numbers
1 33963 42M ACCEPT all -- any any anywhere anywhere state RELATED,ESTABLISHED
2 0 0 ACCEPT icmp -- any any anywhere anywhere
3 44 2602 ACCEPT all -- lo any anywhere anywhere
4 1 60 ACCEPT tcp -- any any anywhere anywhere state NEW tcp dpt:ssh
5 2 112 REJECT all -- any any anywhere anywhere reject-with icmp-host-prohibited
додаю два правила перед останнім reject‘ом, і зберігаю:
vm2 #> iptables -t filter -I INPUT 5 -p tcp --dport 53 -j ACCEPT
vm2 #> iptables -t filter -I INPUT 6 -p udp --dport 53 -j ACCEPT
vm2 #> service iptables save
перевірка з іншої машини в тестлабі — наразі в мене є лише vm1 (spacewalk) — answer section має містити ip ресурса (172.217.13.110), а поле server у частині additional section ― ip сервера dns (192.168.101.102):
vm1 #> drill -4 @192.168.101.102 google.com
працює; залишаю 192.168.101.102 єдиним сервером dns у файлі /etc/resolv.conf на машині vm1 (spacewalk). простий dns на базі dnsmasq готовий.
3.3.3. налаштування dhcp з використанням dnsmasq
dhcp вимагатиме відкритого порту 67/udp:
vm2 #> iptables -t filter -L INPUT -v --line-numbers
vm2 #> iptables -t filter -I INPUT 7 -p udp --dport 67 -j ACCEPT
vm2 #> service iptables save
налаштування dhcp — в тому ж файлі /etc/dnsmasq.conf (лише те, що не налаштовано ще для dns):
## важливо! це єдиний dhcp в тестовій мережі
dhcp-authoritative
## типовий шлюз (default gateway) — сервер віртуалізації roku
dhcp-option=3,192.168.101.1
## dns для клієнтів dhcp — vm2 (опційно, бо dnsmasq анонсує себе)
dhcp-option=6,192.168.101.102
## діапазон для роздачі ipv4: 150-250/24
dhcp-range=192.168.101.150,192.168.101.250,24h
перевіряю конфігурацію і перезавантажую сервіс:
vm2 #> dnsmasq --test
vm2 #> /etc/init.d/dnsmasq restart
для перевірки — спробую створити найменшу можливу віртуальну машинку test на centos 6 (512 мб оперативки, 5 гб дискового простору) і отримати ip по dhcp… для цього єдине, що треба зробити після завантаження — поміняти рядок onboot у файлі /etc/sysconfig/network-scripts/ifcfg-eth0 на yes і перезапустити мережевий сервіс:
test #> service network restart
...
Bringing up interface eth0:
Determining IP information for eth0... done.
[ OK ]
машина отримала адресу по dhcp:
test #> ip address
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:d9:40:20 brd ff:ff:ff:ff:ff:ff
inet 192.168.101.169/24 brd 192.168.101.255 scope global eth
файл /etc/resolv.conf також змінений клієнтом dhcp і містить посилання на мій dns:
cat /etc/resolv.conf
; generated by /sbin/dhclient-script
search lab
nameserver 192.168.101.102
/i\ цікаво було би зрозуміти, чому перша (і єдина наразі — перевірив у файлі /var/lib/dnsmasq/dnsmasq.leases) видана адреса — 169, якщо діапазон задано 150-250? відповідь, що схожа на правду, знайшлася на superuser.com: аби знизити ймовірність зміни адреси, якщо клієнт «спізнився» з поновленням (буває, якщо клієнтські машини вимикаються надовго) — dnsmasq враховує хеш клієнтської mac-адреси, коли вибирає ip. якщо справді потрібно цього уникнути, і радше роздавати адреси послідовно — є опція dhcp-sequential-ip.
3.4. мережеве завантаження (pxe)
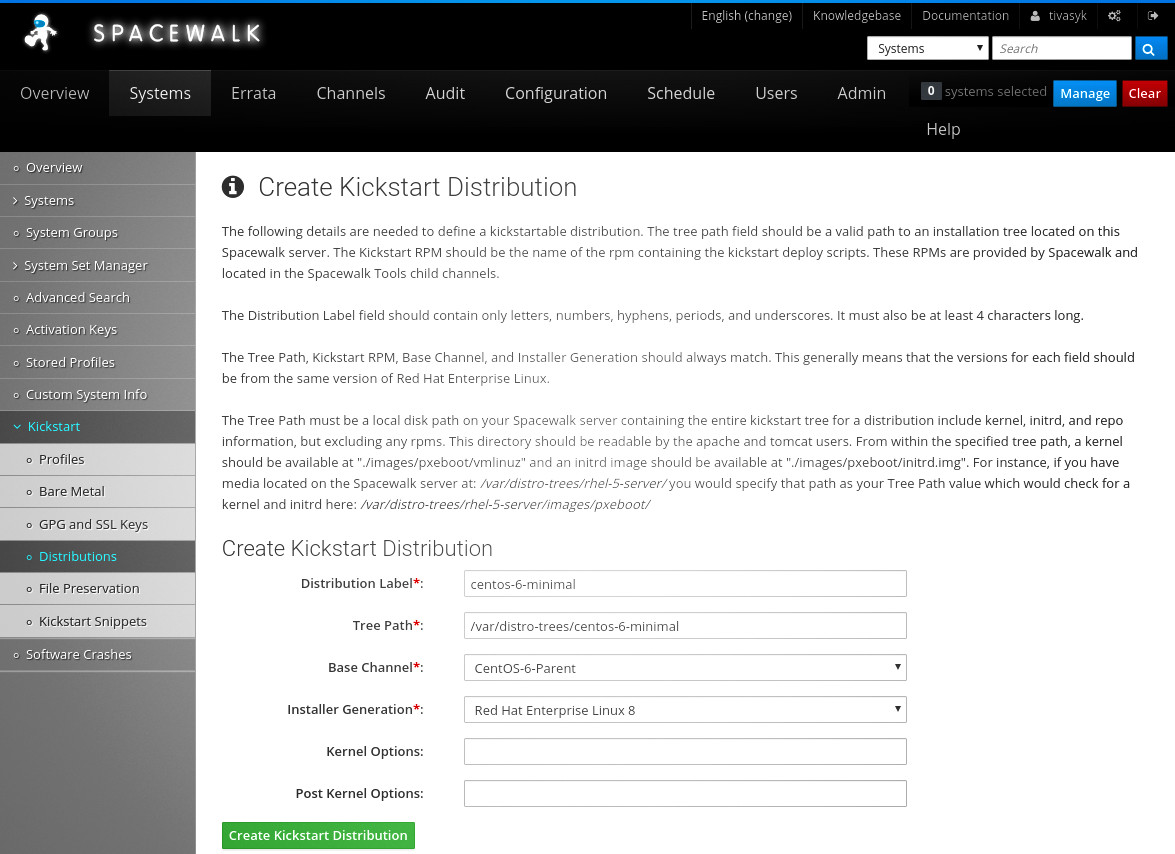
3.4.1. кікстарт на сервері spacewalk
vm1 правує за сервер spacewalk, котрий вміє робити kickstart за допомогою cobbler. спробую налаштувати.
## завантажую centos 6 до /tmp
vm1 #> wget -P /tmp/ ttps://mirrors.edge.kernel.org/centos/6/isos/x86_64/CentOS-6.10-x86_64-minimal.iso
## монтую завантажений образ в теку
vm1 #> mkdir /mnt/centos-6-minimal
vm1 #> mount -o loop /tmp/CentOS-6.10-x86_64-minimal.iso /mnt/centos-6-minimal
## створюю теку для kickstart'а
vm1 #> mkdir /var/distro-trees/
## копіюю туди вміст iso
cp -r /mnt/centos-6-minimal /var/distro-trees/
у веб-інтерфейсі spacewalk створюю дистро kickstart (system > kickstart > distributions > create…), і…
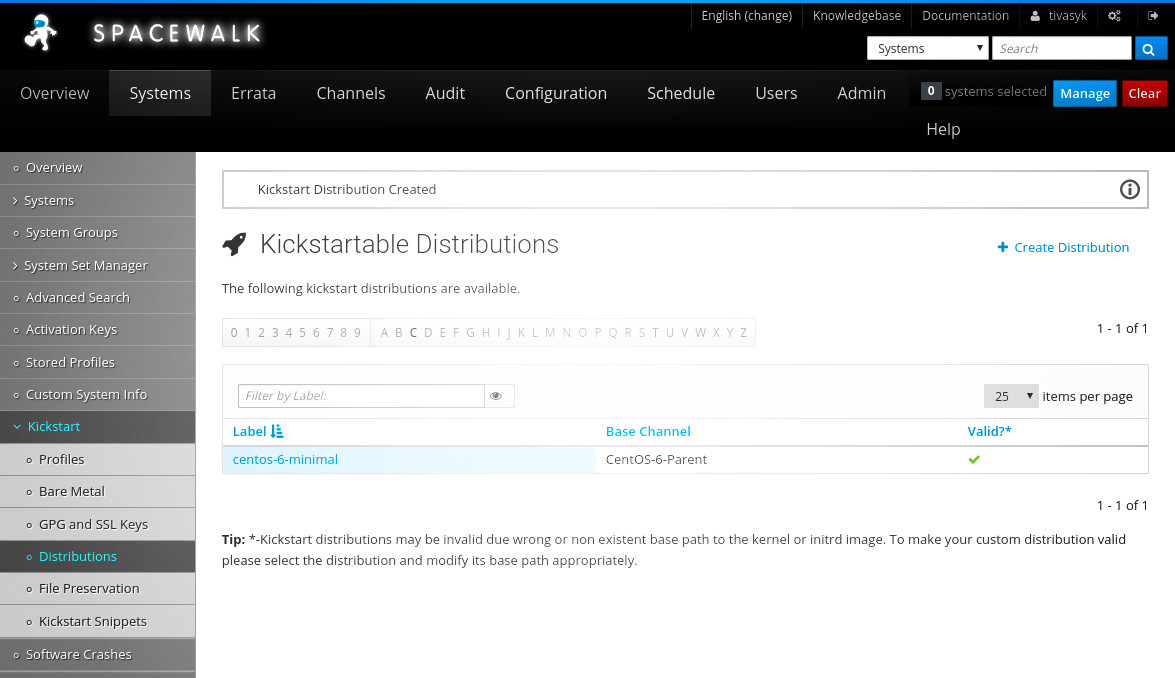
/!\ пшик: «the kernel could not be found at the specified location…» — при цьому vmlinuz точно є там, де spacewalk хоче його знайти.
пригадую, що на очі траплялася заувага щодо selinux для цієї теки… але для spacewalk потрібен інший контекст selinux — spacewalk_data_t. пробую:
vm1 #> /usr/sbin/semanage fcontext -a -t spacewalk_data_t "/var/distro-trees(/.*)?"
vm1 #> /sbin/restorecon -R /var/distro-trees
після цього spacewalk побачив ядро і створив мені дистрибутив для kickstart’у.
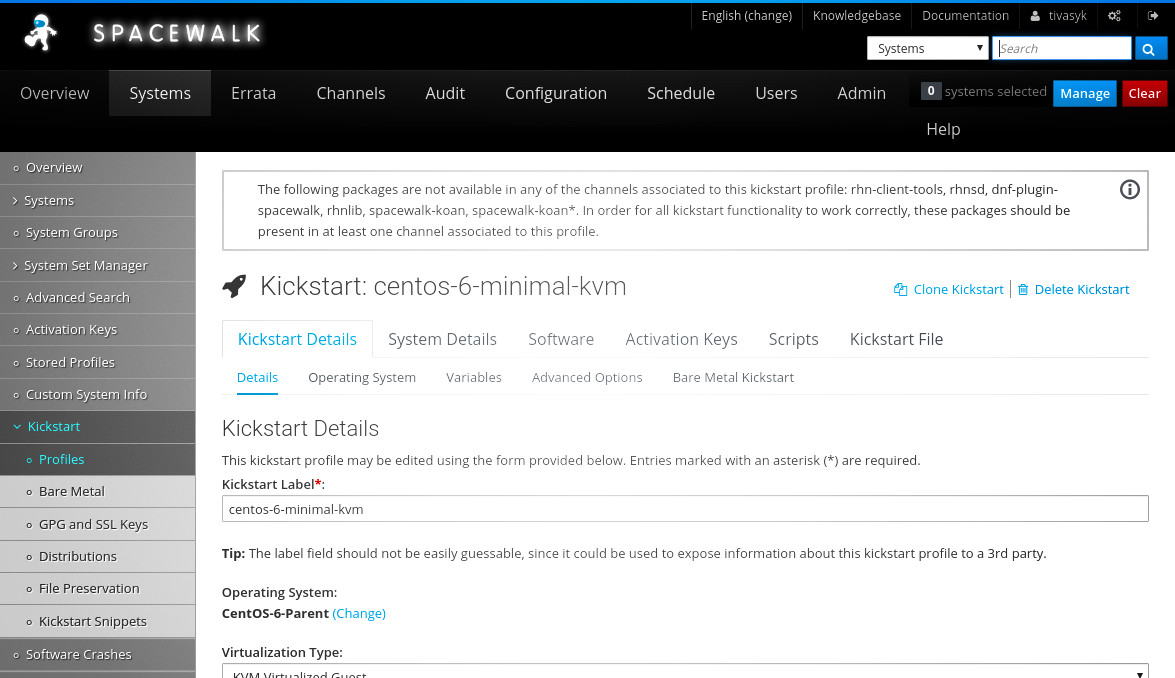
стврюю профіль для kickstart’у: centos-6-minimal-kvm, тип віртуалізації — kvm virtalized guest, типове розташування (/ks/dist/org/1/centos-6-minimal), вказую пароль для root’а на встановлених системах. далі отримую екран налаштування віртуальної машини (через вибір типу віртуалізації, мабуть); з важливого тут (на кожній сторінці треба тиснути «update kickstart», якщо щось змінюється):
- kickstart details
- details
- тип віртуалізації — kvm virtualized guest;
- оперативна пам’ять — 1024 гб (завжди можна поміняти згодом);
- дисковий простір — 10 гб (безпечний мінімум);
- віртуальний міст — virbr101;
- details
- system details
- gpl & ssl
- rhn-org-trusted-ssl-cert
- gpl & ssl
- activation keys
- 1-centos-6-multikey
здається, це все на боці spacewalk? здається, ще ні, бо spacewalk показує попередження: «the following packages are not available in any of the channels associated to this kickstart profile: rhn-client-tools, rhnsd, dnf-plugin-spacewalk, rhnlib, spacewalk-koan, spacewalk-koan*. in order for all kickstart functionality to work correctly, these packages should be present in at least one channel associated to this profile».
далі курю мануал читаю підказку… мені потрібен підканал (child channel) з кількома додатковими пакунками. підказка підказує (с) завантажити необхідні rpm’и і додати до підканалу руками… але чому не зробити те, для чого й придумали spacewalk — додати репозиторій і дозволити програмі робити справу? пробую — і чекаю, поки spacewalk затягне потрібні пакунки.
/!\ чекав довго — не вичекав: перелік пакунків репозиторія centos6kickstart порожній. журнал taskomatic (/var/log/rhn/rhn_taskomatic_daemon.log) містить криптичні повідомлення про 0 пакунків у репозиторії, відповідного журналу для reposync () немає… хз, що відбувається. спроба запустити spacewalk-repo-sync вручну:
vm1 #> spacewalk-repo-sync --channel centos6kickstart --type yum
ERROR: attempting to run more than one instance of spacewalk-repo-sync Exiting.
отже, процес десь крутиться, але жодного відгуку від нього в журналах немає… ризикну «прибити» його і пробую ще раз руками, вказавши ще й джерело для надійности:
vm1 #> killall spacewalk-repo-sync
vm1 #> spacewalk-repo-sync --channel centos6kickstart --type yum -u http://mirrors.maine.edu/spacewalk/2.9-client/RHEL/6/x86_64/
в консолі бачу, що 74 пакунки завантажилися, що журнал reposync.log містить згадку про початок синхронізації, а reposync/centos6kickstart.log — про реєстрацію в базі даних… але далі скрипт «зависає», здається:
Importing packages to DB:
Importing packages: |######--------------------------------------------| 12.16%
перезавантаження сервіса postgresql і перезапуск синхронізації, здається, допомогли:
vm1 #> service postgresq restart
vm1 #> vm1 #> spacewalk-repo-sync --channel centos6kickstart --type yum -u http://mirrors.maine.edu/spacewalk/2.9-client/RHEL/6/x86_64/
дуже дивно, і мені це не подобаться, — сподіваюся, не доведеться ніколи підтримувати spacewalk в продакшні. важливо, що потрібні пакунки затяглися до підканалу.
3.4.2. опція dhcp-boot для dnsmasq
dnsmasq має інтегровані сервери pxe та tftp для мережевого завантаження, але вони мені не потрібні; формат опції dhcp-boot дозволяє вказати сторонній сервер; пробую таке:
dhcp-boot=pxelinux.0,spacewalk.lab,192.168.101.101
час спробувати? якщо я все налаштував як слід — треба лише замінити --location=... (шлях до iso) замінити на коротке --pxe:
roku #> virt-install \
--virt-type=kvm \
--name vm3 \
--ram 1024 \
--vcpus=1 \
--os-variant=rhel6 \
--hvm \
--nographics \
--pxe \
--network bridge=virbr101,model=virtio \
--disk path=/var/lib/libvirt/images/vm3.qcow2,size=30,bus=virtio,format=qcow2 \
…і тиша: переметр --extra-args знову недоступний, в консолі нічого від віртуальної машини немає. на гіпервізорі бачу, що машина «крутиться»:
roku #> virsh --connect qemu:///system list --all
Id Name State
----------------------
4 vm1 running
6 vm2 running
8 test running
9 vm3 running
…а на сервері dhcp бачу, що їй видано адресу (242, без імені вузла):
vm2 #> cat /var/lib/dnsmasq/dnsmasq.leases
1598798240 52:54:00:37:96:8d 192.168.101.242 * 01:52:54:00:37:96:8d
1598797973 52:54:00:d9:40:20 192.168.101.169 test *
але машина не пінгується. поки що не придумав, як підглянути, що відбувається насправді. або я щось зробив не як слід, або… я все зробив не так як треба. пройдуся з перевіркою…
1) чи відкрито порт 69/udp (tftp) на сервері pxe (vm1.lab)? — так (і лічильник пакунків показує два запити):
vm1 #> iptables -t filter -L INPUT -v --line-numbers
Chain INPUT (policy ACCEPT 9 packets, 3576 bytes)
num pkts bytes target prot opt in out source destination
...
8 2 136 ACCEPT udp -- any any anywhere anywhere udp dpt:tftp
/i\ деякі підказки згадують 69/tcp, але це, гхм, дивно.
2) чи поновив я ключ активації centos-6-multikey, що його використовує kicktart centos-6-minimal, коли додав підканал/репозиторій для kickstart’у? — ні. хз, чи це допоможе, але — fixed.
3) чи працює сервіс tftp на сервері spacewalk (vm1.lab)? — так:
vm1 #> service xinetd status
xinetd (pid 1232) is running...
конфігурація (/etc/xinitd/tftp) підказує, що роздається тека /var/lib/tftpboot. вміст теки:
drwxr-xr-x. 2 root root 4096 Aug 28 18:50 aarch64
drwxr-xr-x. 2 root root 4096 Aug 28 18:50 etc
drwxr-xr-x. 2 root root 4096 Aug 28 18:50 grub
drwxr-xr-x. 3 root root 4096 Aug 28 18:50 images
drwxr-xr-x. 2 root root 4096 Aug 28 18:50 ppc
drwxr-xr-x. 2 root root 4096 Aug 28 18:50 pxelinux.cfg
drwxr-xr-x. 2 root root 4096 Aug 28 18:50 s390x
з сусідньої машини пробую забрати файл pxelinux.cfg/default — отримую permission denied:
roku $> tftp 192.168.101.101
tftp> get pxelinux.cfg
tftp: pxelinux.cfg: Permission denied
гхм, я намагаюся забрати файл до теки, куди я не маю права писати =) виправився:
roku $> tftp 192.168.101.101
Received 581 bytes in 0.0 seconds
дивлюся файл — схоже на меню завантаження:
DEFAULT menu
PROMPT 0
MENU TITLE Cobbler | http://fedorahosted.org/cobbler
TIMEOUT 200
TOTALTIMEOUT 6000
ONTIMEOUT local
LABEL local
MENU LABEL (local)
MENU DEFAULT
LOCALBOOT 0
LABEL centos-6-minimal-kvm:1:Testlab
kernel /images/centos-6-minimal:1:Testlab/vmlinuz
MENU LABEL centos-6-minimal-kvm:1:Testlab
append initrd=/images/centos-6-minimal:1:Testlab/initrd.img ksdevice=bootif lang= kssendmac text ks=http://127.0.1.1/cblr/svc/op/ks/profile/centos-6-minimal-kvm:1:Testlab
ipappend 2
MENU end
чому там 127.0.1.1? дивно… здається, мені треба зробити перерву в експериментах і подумати:
- знайти детальну, покрокову підказку щодо налаштування мережевого завантаження, щоби пройтися й перевірити замість блукати навпомацки?
- як достукатися до інтерфейсу віртуальної машини на етапі, коли систему ще не встановлено і ані ssh, ані текстовий термінал не доступні?
- спробувати виключити з рівняння spacewalk і налаштувати якийсь найпростіший варіант, суто на dnsmasq?
далі буде…
додатки
використані довідкові матеріяли
те, що мені видалося найкращим (найповніше, найзрозуміліше пояснено тощо) — позначив /!\.
віртуалізація з qemu/kvm
- книжка «kvm virtualization cookbook» — коштує 33$ на packt’і, але pdf знайшовся в тенетах, гхм…
- підручник «virtualization deployment and administration guide» на redhat.com
налаштування віртуальної мережі для qemu/kvm
- розділ «setting up bridge networking» у вікі debian — плутаний і не дуже помічний
- розділ «bridge network connections» у вікі debian — посилається на потрібні інструменти (
brctlне встановлений «з коробки» разом з debian) - розділ «networking» на libvirt.org — детально про ізольовану (virtual) мережу та спільний міст, але нічого про маршрутизацію
- розділ «configuring guest networking» на офіційному вебсайті kvm — згадка про маршрутизовані гостьові мережі на iptable
- покрокова підказка «kvm: creating a guest vm on a network in routed mode» — детально про «як», але мало про «чому»
- /!\ підручник «libvirt networking handbook» на сайті jemielinux.com — досить детально (з поясненнями) про різні варіанти підключеня віртуалок до мережі
зміна розміру розділів, фізичних та логічних томів lvm
- підказка «centos / rhel : how to extend physical volume in lvm by extending the disk partition used» на thegeekdiary.com
- /!\ дві статті «resizing a kvm disk image on lvm, the hard way», «resizing a kvm disk image on lvm, the easy way» на dnaeon.github.io — дуже детально, з покроковими командами та поясненнями
налаштування iptables
- величезний посібник «iptables tutorial» на frozentux.net — дуже детальна теорія про все, але мені бракує «живих» прикладів
- посібник «an in-depth guide to iptables, the linux firewall» на booleanworld.com — значно коротший, але простіший для розуміння, з прикладами
spacewalk
- довідник spacewalk user documentation на сайті spacewalk
- підказка «spacewalk for linux management» на medium.com — з трьох частин («setting up spacewalk channels», «registering spacewalk clients»)
- довідник «spacecmd reference» на suse.com
- огляд «the story of errata for centos» на petersouter.xyz — короткий огляд різних способів обійти брак офіційного джерела errata для centos
- довідник «setting up kickstart trees» на oracle.com
dnsmasq: сервер dhcp/dns
- /!\ розділ «dnsmasq» у вікі arch linux
- домашня сторінка dnsmasq і довідник (manpage) на thekelleys.org.uk
- документ «dhcp and bootp parameters» на iana.org — перелік опцій dhcp
оригінальний допис на r/linuxadmin
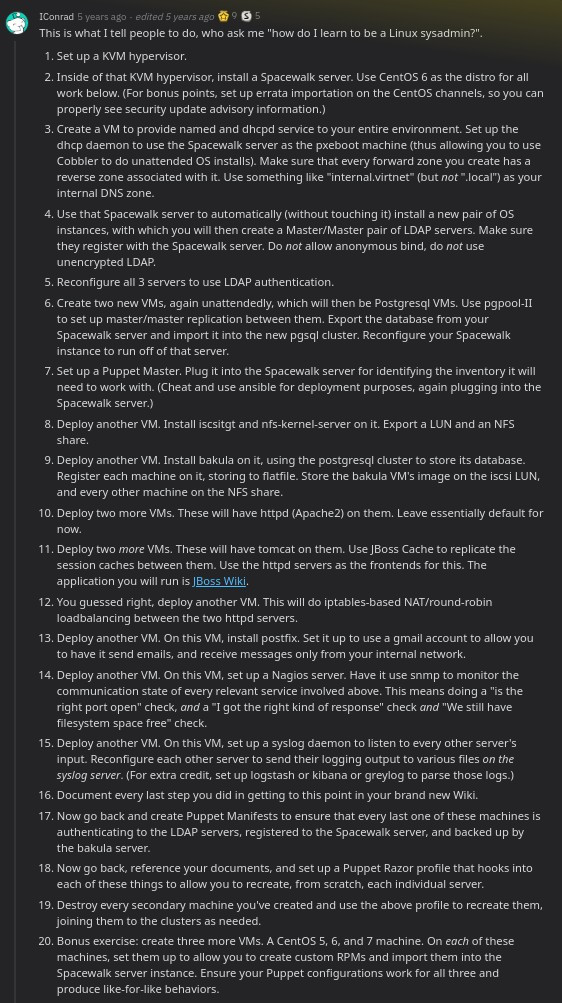
перелік віртуальних машин
формат: задача: роль ×кількість
- 2: spacewalk ×1
- 3: dns/dhcp ×1
- 4: ldap ×2
- 6: postgress ×2
- 7: puppet ×1
- 8: nfs ×1
- 9: bakula ×1
- 10: httpd ×2
- 11: tomcat/jboss ×2
- 12: http loadbalancer ×1
- 13: postfix ×1
- 14: nagios ×1
- 15: syslog ×1
- 16: centos clients ×3