моєму домашньому серверу — півтора роки, якщо вважати день запуску першого сервісу (owncloud) за його «день народження». за весь час перезавантажувався двічі — раз через тривале відключення електрики (ups не витримав), другий раз вже не пригадаю навіщо. на сервері крутяться щоденник (jekyll, lighttpd), pi-hole та owncloud. мені, до речі, сподобався docker для запуску сервісів — трохи мороки на старті через брак документації, але далі зазвичай все просто працює без потреби «адмініструвати» сервер.
і все було би чудово, не треба було би нічого міняти, якби не owncloud — не лише я, але й родина звикли вивантажувати туди світлини й відео з телефонів, плюс звідти роздаються (привезені ще з україни) фільми, по dlna на телевізор… але файлове сховище досі залежить від одного-єдиного диска, без бекапів, і це рецепт маленької катастрофи. плюс хочеться більше місця на owncloud (хоча й ті 500 гб поки що зайняті лише на третину).
звідси два сценарії крутяться в голові: проапгрейдити цей старенький hp compaq dc5800, додавши другий диск для копіювання всього вмісту owncloud? або зібрати заміну на базі hp compaq 8100 elite, що впав мені до рук днями? теж старий мотлох, але intel core i5-650 замість pentium e5200 і ddr3 1333 ггц замість ddr2 800 ггц, плюс можна гратися з налаштуванням, не ламаючи того, що є зараз, і мігрувати, коли готовий.
зміст
проєкт
- викинути оптичний дисковод, звільнивши місце для бекплейна на 6 дисків sata 2,5” (вже придбав для цього дешевий китайський olmaster c3804, чи oimaster? біс їх розбереш) для простого доступу до дисків;
- забити бекплейн дешевими дисками;
- вирішити щось із дублюванням чи резервним копіюванням: zfs? btrfs? чи просто ext4+mergefs+snapraid? чи навіть просто два розділи lvm в програмному raid0?;
- спробувати nextcloud замість owncloud (бо розвинутіший набір аплетів, який майже може замінити google колись);
- налаштувати автогасіння сервера від ups під час відключення електрики;
- (опційно) налаштувати резервне копіювання до aws?
- (опційно) спробувати підняти всі сервіси на «голому» debian (або proxmox’і) за допомогою лише ansible?

витрати
- hp compaq 8100 elite (без дисків і лише з 2 гб пам’яті) = 0,00$
- бекплейн olmaster c3804 (aliexpress) = 65,95$
- адаптер pcie до sata x4 iocrest si-pex40064 (kijiji) = 30,00$
- адаптер живлення sata до molex для бекплейна (amazon) = 10,34$
- пам’ять 4×4 гб (amazon) = 105,75$
- системний ssd 240 гб kingston a400 (amazon) = 45,95$
- диски «зі сміттярки»
- 2×500 гб seagate momentus thin 2,5” sata (kijiji) = 30,00$
- 4×500 гб hitachi travelstar 2,5” sata (kijiji) = 60,00$
вартість повна (з доставкою і податками) в канадійських доларах (cad).

встановлення базової системи
на перший погляд, hp compaq 8100 elite — не така вже й старезна система, але примхлива: з першої спроби відмовилася завантажувати debian (9.9.0 netinst) та proxmox (6.1) з перевірених флешок, — але завантажила clonezilla (2.6.4.10), xcp-ng (8.1) та, зненацька, manjaro (kde 18.1.5 minimal).
я вже збирався трясти бубном, але наостанок спробував перезаписати debian 10 на флешку не так, як зазвичай (dd), а як книжка пише:
# cp debian-*-amd64-netinst.iso /dev/sdX && sync
хз, чому dd виявився недостатньо хороший для цієї материнки, але тут все «завелося», тож далі встановлюю debian як зазвичай. після налаштування статичного ip, sudo для користувача, сервера ssh — можна йти «курити» ansible, мабуть?
але тут я задумався: граючись із ansible, я гарантовано поламаю систему, і не раз. доведеться знову перевстановлювати руцями? було би значно простіше мати під сподом гіпервізор, і бекапити/відновлювати віртуальну машину з debian стільки разів, скільки треба, в тому числі й за допомогою того ж таки ansible. proxmox виглядає як найкращий варіант для домашнього використання, але оскільки з флешки він ніяк не хоче завантажуватися на цій машині, довелося зробити руцями.
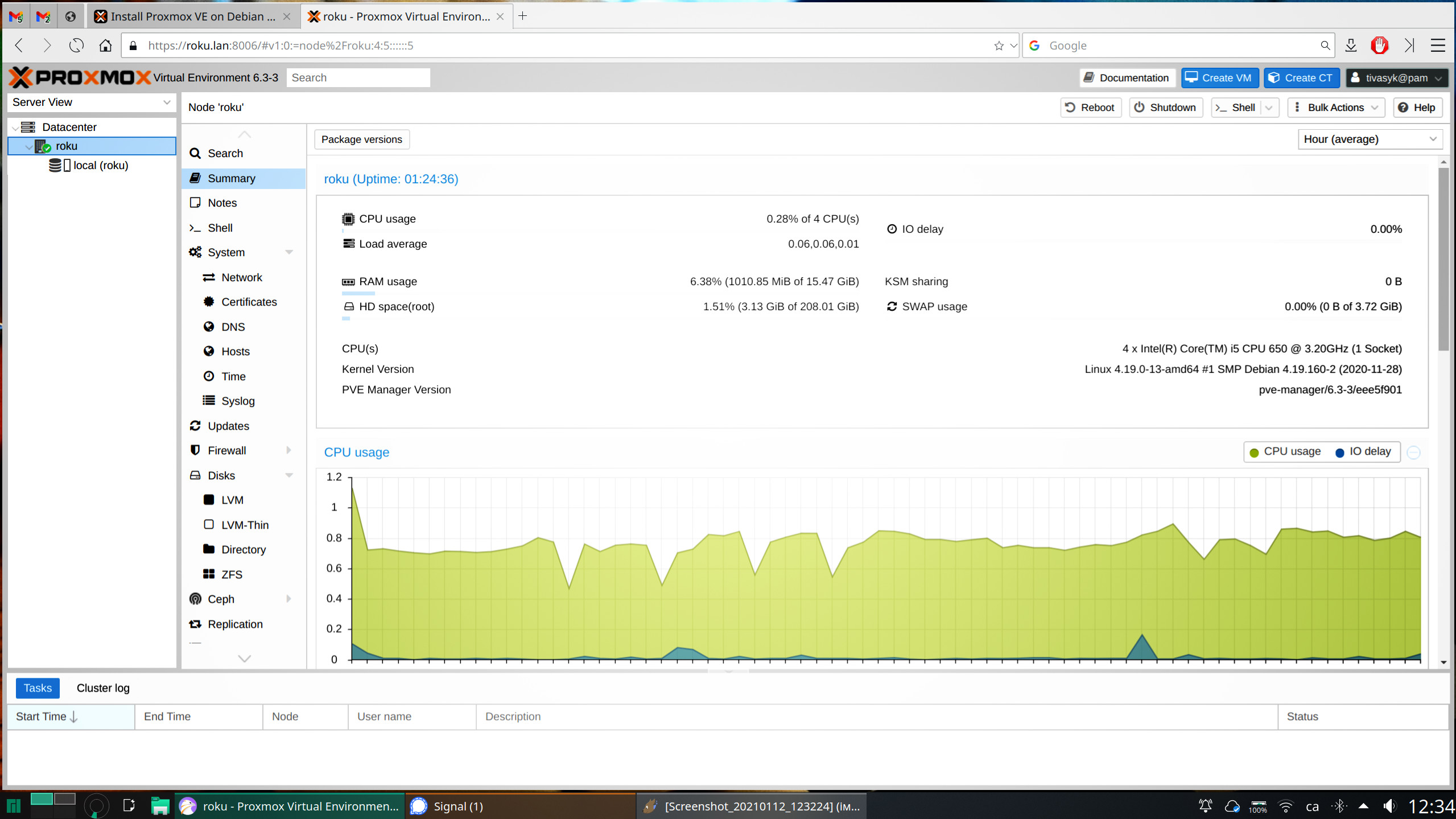
аж от тепер можна йти «курити» ansible довго думав, і врешті-решт відклав ansible на десерт: пограюся, коли вже буде робоча система. окрім цього, деякий час я серйозно схилявся до думки відмовитися від розваги налаштувати все руками на proxmox і спробувати готовий unraid… але вирішив, що трохи додаткового досвіду не зашкодить.
дискове сховище
перші враження від бекплейна olmaster c3804: якість не вражає (лотки вимагають значної уваги при встромлянні, діоди статусу дуже різної яскравости тощо), але для домашнього використання має бути придатне.
далі має бути азбац про вибір архітектури для файлосховища; зокрема — чому mergerfs та snapraid, а не щось серйозніше, як zfs. якщо коротко: тому що «простота є необхідною передумовою надійност軆. так і не знайшов притомної детальної підказки з налаштування proxmox + mergerfs + snapraid в тенетах, доведеться експериментувати.
додавання дисків
на kijiji придбав шість накопичувачів sata 2,5” по 500 гб (15 $/диск) на kijiji; ще один уже мав у зовнішній кишені usb 3.0 — залишу на випадок заміни.
$ lsblk -o NAME,SIZE,TYPE,HCTL,MODEL,SERIAL,LABEL,MOUNTPOINT
NAME SIZE TYPE HCTL MODEL SERIAL LABEL MOUNTPOINT
sda 223.6G disk 0:0:0:0 KINGSTON_SA400S37240G 50026B7783A6A3BB
├─sda1 212.3G part System /
└─sda2 3.7G part [SWAP]
sdb 465.8G disk 6:0:0:0 HGST_HTS725050A7E630 TF755AWHJ90N3M
sdc 465.8G disk 2:0:0:0 ST500LM021-1KJ152 W621S841
sdd 465.8G disk 7:0:0:0 HGST_HTS725050A7E630 TF755AWHJ8EKSM
sde 465.8G disk 1:0:0:0 ST500LM000-1EJ162 W371AHNV
sdf 465.8G disk 8:0:0:0 HGST_HTS725050A7E630 TF755AWHH65J0K
sdg 465.8G disk 9:0:0:0 HGST_HTS725050A7E630 TF655AWJ15V7BL
hctl ― ідентифікатор фізичного підключення у форматі scsi, в моєму випадку 0..2 — роз’єми sata на материнській платі, 6..9 — на додатковому адаптері pcie до sata… може знадбитися, як спосіб ідентифікувати диски та кишеньки бекплейна; мої піключені так:
┌───────┬───────┐
│6:0:0:0│7:0:0:0│
├───────┼───────┤
│8:0:0:0│9:0:0:0│
├───────┼───────┤
│1:0:0:0│2:0:0:0│
└───────┴───────┘
але для автоматичного монтування в fstab не можна використовувати htcl, тому варто давати дискам якісь впорядковані мітки: п’ять дисків (data1..data5) міститимуть дані, доступні (через mergerfs) як одна тека (storage), а шостий (parity1) — слугуватиме сховищем контрольної суми (parity) для snapraid. схема монтування:
/mnt
├─disk
│ ├─data1
│ │ …
│ ├─data5
│ └─parity1
└─storage
створюю по одному розділу на кожному диску, форматую ext4 з відповідною міткою:
# fdisk /dev/sdb # 6:0:0:0
# mkfs.ext4 -m 1 -L Data1 /dev/sdb1
...
# fdisk /dev/sdd # 7:0:0:0
# mkfs.ext4 -m 1 -L Data2 /dev/sdd1
...
# fdisk /dev/sdc # 2:0:0:0
# mkfs.ext4 -m 0 -T largefile4 -L Parity1 /dev/sdc1
результат: п’ять дисків з мітками data1..5 і один — parity1:
$ lsblk -o NAME,SIZE,TYPE,HCTL,MODEL,SERIAL,LABEL,MOUNTPOINT
NAME SIZE TYPE HCTL MODEL SERIAL LABEL MOUNTPOINT
sda 223.6G disk 0:0:0:0 KINGSTON_SA400S37240G 50026B7783A6A3BB
├─sda1 212.3G part System /
└─sda2 3.7G part [SWAP]
sdb 465.8G disk 6:0:0:0 HGST_HTS725050A7E630 TF755AWHJ90N3M
└─sdb1 465.8G part Data1
sdc 465.8G disk 2:0:0:0 ST500LM021-1KJ152 W621S841
└─sdc1 465.8G part Parity1
sdd 465.8G disk 7:0:0:0 HGST_HTS725050A7E630 TF755AWHJ8EKSM
└─sdd1 465.8G part Data2
sde 465.8G disk 1:0:0:0 ST500LM000-1EJ162 W371AHNV
└─sde1 465.8G part Data5
sdf 465.8G disk 8:0:0:0 HGST_HTS725050A7E630 TF755AWHH65J0K
└─sdf1 465.8G part Data3
sdg 465.8G disk 9:0:0:0 HGST_HTS725050A7E630 TF655AWJ15V7BL
└─sdg1 465.8G part Data4
готую директорії для монтування дисків:
# mkdir /mnt/disk/data{1,2,3,4,5}
# mkdir /mnt/disk/parity1
додаю щось таке до fstab (не забути резервну копію перед редагуванням), щоби монтувати диски в бекплейні за мітками розділів (label):
# Storage backplane for 6 SATA disks
# Mount is by volume label (not PARTLABEL though),must avoid duplicates
# <file system> <mount point> <type> <options> <dump> <pass>
LABEL=Data1 /mnt/disk/data1 ext4 defaults,nofail,x-systemd.device-timeout=9 0 2
LABEL=Data2 /mnt/disk/data2 ext4 defaults,nofail,x-systemd.device-timeout=9 0 2
LABEL=Data3 /mnt/disk/data3 ext4 defaults,nofail,x-systemd.device-timeout=9 0 2
LABEL=Data4 /mnt/disk/data4 ext4 defaults,nofail,x-systemd.device-timeout=9 0 2
LABEL=Data5 /mnt/disk/data5 ext4 defaults,nofail,x-systemd.device-timeout=9 0 2
LABEL=Parity1 /mnt/disk/parity1 ext4 defaults,nofail,x-systemd.device-timeout=9 0 2
монтування на випробу (згодом монтуватиметься автоматично під час завантаження системи), і перевірка:
# mount -a
$ lsblk -o NAME,SIZE,TYPE,HCTL,MODEL,SERIAL,LABEL,MOUNTPOINT
NAME SIZE TYPE HCTL MODEL SERIAL LABEL MOUNTPOINT
sda 223.6G disk 0:0:0:0 KINGSTON_SA400S37240G 50026B7783A6A3BB
├─sda1 212.3G part System /
└─sda2 3.7G part [SWAP]
sdb 465.8G disk 6:0:0:0 HGST_HTS725050A7E630 TF755AWHJ90N3M
└─sdb1 465.8G part Data1 /mnt/disk/data1
sdc 465.8G disk 2:0:0:0 ST500LM021-1KJ152 W621S841
└─sdc1 465.8G part Parity1 /mnt/disk/parity1
sdd 465.8G disk 7:0:0:0 HGST_HTS725050A7E630 TF755AWHJ8EKSM
└─sdd1 465.8G part Data2 /mnt/disk/data2
sde 465.8G disk 1:0:0:0 ST500LM000-1EJ162 W371AHNV
└─sde1 465.8G part Data5 /mnt/disk/data5
sdf 465.8G disk 8:0:0:0 HGST_HTS725050A7E630 TF755AWHH65J0K
└─sdf1 465.8G part Data3 /mnt/disk/data3
sdg 465.8G disk 9:0:0:0 HGST_HTS725050A7E630 TF655AWJ15V7BL
└─sdg1 465.8G part Data4 /mnt/disk/data4
smart
після підключення дисків варто перевірити звіти smart. по-перше — короткий тест для шести дисків у бекплейні (/dev/sdX):
# for X in b c d e f g; do echo -n "/dev/sd${X}: "; smartctl -t short /dev/sd${X} | grep "complete after"; done
/dev/sdb: Test will complete after Thu Feb 4 23:16:48 2021 EST
/dev/sdc: Test will complete after Thu Feb 4 23:15:48 2021 EST
/dev/sdd: Test will complete after Thu Feb 4 23:16:50 2021 EST
/dev/sde: Test will complete after Thu Feb 4 23:16:50 2021 EST
/dev/sdf: Test will complete after Thu Feb 4 23:16:51 2021 EST
/dev/sdg: Test will complete after Thu Feb 4 23:16:53 2021 EST
за якийсь час (дві хвилини для сучасних hdd) перевіряю результат:
# for X in b c d e f g; do echo -n "/dev/sd${X}: "; smartctl -H /dev/sd${X} | grep "result"; done
/dev/sdb: SMART overall-health self-assessment test result: PASSED
/dev/sdc: SMART overall-health self-assessment test result: PASSED
/dev/sdd: SMART overall-health self-assessment test result: PASSED
/dev/sde: SMART overall-health self-assessment test result: PASSED
/dev/sdf: SMART overall-health self-assessment test result: PASSED
/dev/sdg: SMART overall-health self-assessment test result: PASSED
наразі все гаразд. якщо знадобиться переглянути детальний звіт для котрогось із дисків:
# smartctl -a /dev/sdb
mergerfs
встановлення mergerfs елементарне (знадобиться також fuse, але воно «з коробки» є):
# apt-get update && apt-get install mergerfs
тека, куди «об’єднаються» розділи на п’ятьох дисках dataX у бекплейні:
# mkdir /mnt/storage
даю доступ усім користувачам:
# chmod -R a+rwx /mnt/storage
додаю автомонтування до /etc/fstab:
# MergerFS pool
# <file system> <mount point> <type> <options> <dump> <pass>
/mnt/disk/data* /mnt/storage fuse.mergerfs defaults,allow_other,use_ino,nonempty,direct_io,fsname=mergerfs,minfreespace=20G 0 0
монтую:
# mount -a
за підказкою на сайті mergerfs, перевірю швидкодію, згенерувавши сто гігабайтових файлів до /mnt/storage:
for ((i=1; i<=100; i++)); do echo "File: test_${i}.tmp..."; dd if=/dev/zero of=/mnt/storage/test_${i}.tmp bs=1M count=1024 oflag=nocache conv=fdatasync status=progress; done
у сусідньому терміналі можна спостерігати за наповненням окремих дисків data1..5, та об’єднаної теки /mnt/storage та розподіл записаних файлів по фізичних дисках:
$ watch -n 10 "df -h -t ext4 -t fuse.mergerfs; ls -x /mnt/disk/data*"
snapraid
репозиторії debian не містять snapraid, і здається, що всенький інтернет користується підказкою зі збирання snapraid із сирців у контейнері docker. не найгірший варіант. знадобляться git та docker:
# apt-get update
# apt-get install docker git
всю важку роботу робить контейнер:
$ mkdir ~/tmp && cd ~/tmp
$ git clone https://github.com/IronicBadger/docker-snapraid
$ cd docker-snapraid
$ chmod +x build.sh
$ sudo ./build.sh
якщо все минуло добре, згенерований пакунок для debian лежить у теці ~/doker-snapraid/build, можна встановлювати:
$ sudo dpkg -i ~/docker-snapraid/bild/snapraid-from-source.deb
перевірка:
$ snapraid --version
snapraid v11.5 by Andrea Mazzoleni, http://www.snapraid.it
якщо все гаразд, можна видалити ~/tmp/docker-snapraid. конфігурація snapraid (/etc/snapraid.conf):
# Parity file(s)
parity /mnt/disk/parity1/snapraid.parity
#
# Data disks/storage
data d1 /mnt/disk/data1
data d2 /mnt/disk/data2
data d3 /mnt/disk/data3
data d4 /mnt/disk/data4
data d5 /mnt/disk/data5
#
# Content files (multiple copies)
content /var/.snapraid.content
content /mnt/disk/data1/.snapraid.content
content /mnt/disk/data2/.snapraid.content
content /mnt/disk/data3/.snapraid.content
content /mnt/disk/data4/.snapraid.content
content /mnt/disk/data5/.snapraid.content
#
# Exclude from parity calculation
exclude /lost+found/
exclude /tmp/
після цього, нарешті, можна зробити те, заради чого все й задумано — згенерувати дані парності на диску /mnt/parity1 для відновлення:
$ sudo snapraid sync
на порожніх дисках data1..5 все відбувається дуже швидко. snapraid жаліється, що з п’ятьма дисками варто тримати два диски parity (на випадок відмови двох дисків у бекплейні), але тоді в мене залишиться чотири диски даних… а для них рекомендовано один parity… це як задача про гарну й розумну мавпу, але зациклена =)
snapraid не встановлює сервісів і не автоматизує сам нічого в cron’і — це можна зробити самотужки, але краще скористатися готовим рішенням: snapraid-runner (детальна підказка):
# git clone https://github.com/Chronial/snapraid-runner.git /opt/snapraid-runner
# cp /opt/snapraid-runner/snapraid-runner.conf.example /opt/snapraid-runner/snapraid-runner.conf
основні зміни до конфігурації /opt/snapraid-runner/snapraid-runner.conf:
[snapraid]
executable = /usr/local/bin/snapraid
config = /etc/snapraid.conf
touch = true
; далі опційно
deletethreshold = 250
[scrub]
enabled = true
перевірка (url для інтеграції з healthchecks.io треба згенерувати окремо):
# python3 /opt/snapraid-runner/snapraid-runner.py -c /opt/snapraid-runner/snapraid-runner.conf && curl -fsS --retry 3 https://hc-ping.com/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx > /dev/null
наостанок — cron для snapraid-runner (щоночі о 03:00):
# Snapraid management with snapraid-runner
00 03 * * * python3 /opt/snapraid-runner/snapraid-runner.py -c /opt/snapraid-runner/snapraid-runner.conf && curl -fsS --retry 3 https://hc-ping.com/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx > /dev/null
віртуальна машина для docker
все, що мені треба від сервера, можна підняти в контейнерах просто на базовій системі — як на моєму першому сервері, тож навіщо віртуалізувати? по-перше, забагато досвіду з гіпервізором не буває, якщо я хочу претендувати на більшу з/п. по-друге, переваги віртуалізації можуть стати в пригоді навіть на маленькому домашньому сервері: знятки стану (snapshots), можливість зупинити (віртуальний) сервер, не зупиняючи залізо тощо.
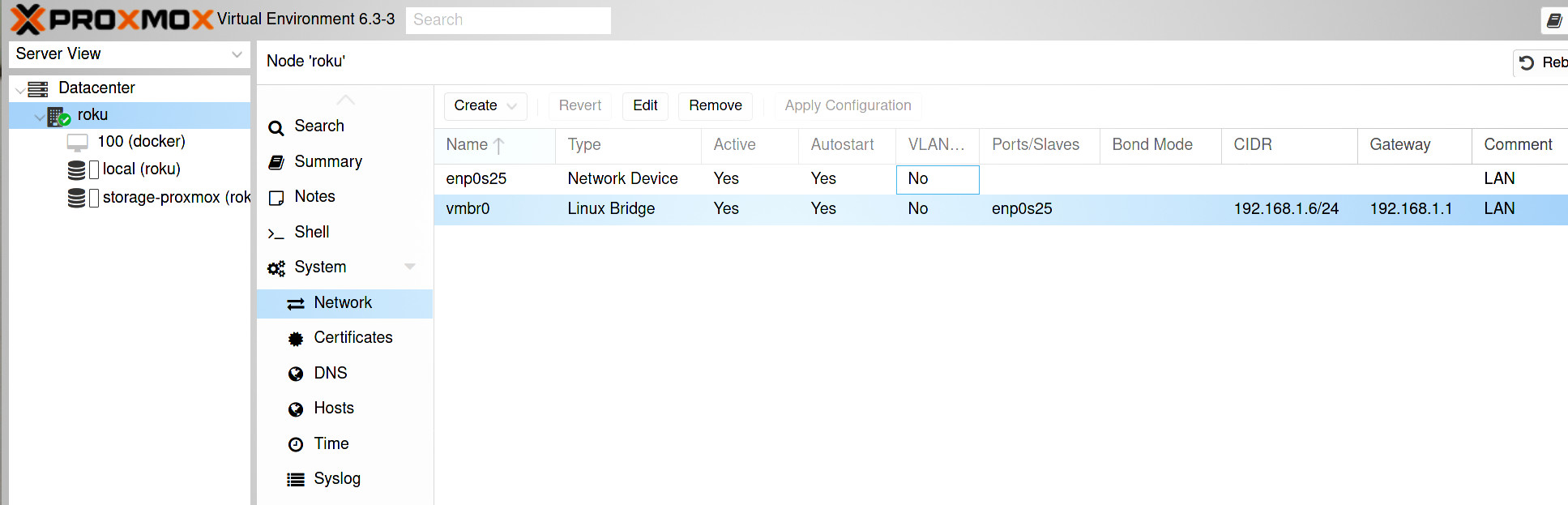
тож… proxmox вже встановлено; ще одна маленька обов’язкова деталь — додати мережевий міст, інакше віртуальні машини будуть без мережі на сервері з лише однією мережевою картою; для цього знадобиться прибрати аресу ip в налаштуваннях мережевого інтерфейсу (enp0s25 в моєму випадку), і віддати її мосту (vmbr0).
далі буде…
† вислів едсгера дейкстри